
MLS-Bench: A Holistic and Rigorous Assessment of AI Systems on Building Better AI
MLS-Bench evaluates whether AI systems can invent generalizable and scalable ML methods. It spans 140tasks across 12 domains — language models, vision and generation, reinforcement learning, robotics, ML systems, AI for science, optimization, time series, causal reasoning, and more.










Methods that stood the test of time and scale.
Modern AI progress is built on a small set of reusable ideas — convolutions, residual connections, attention, normalization — that generalize across architectures and survive every order-of-magnitude jump in scale.
Weight-shared receptive fields that scaled vision models.
Distributed embeddings transferable across NLP tasks.
Adversarial generator–discriminator game for sample synthesis.
Adaptive moment estimation that became the default optimizer.
Encoder–decoder with skip links — vision and diffusion staple.
Clipped policy ratio that made deep RL stable to scale.
Mean-free normalization, faster and surprisingly sufficient.
Rotary position encoding that scales with context length.
IO-aware exact attention that scaled context length.
Weight-shared receptive fields that scaled vision models.
Distributed embeddings transferable across NLP tasks.
Adversarial generator–discriminator game for sample synthesis.
Adaptive moment estimation that became the default optimizer.
Encoder–decoder with skip links — vision and diffusion staple.
Clipped policy ratio that made deep RL stable to scale.
Mean-free normalization, faster and surprisingly sufficient.
Rotary position encoding that scales with context length.
IO-aware exact attention that scaled context length.
Gated recurrence enabling long-range sequence learning.
Random unit masking that became the standard regularizer.
Normalizing activations across the batch to stabilize training.
Residual connections enabling 100+ layer training.
Self-attention as the universal sequence operator.
Input–label interpolation that improved generalization.
Denoising diffusion: learn to invert a noise process.
Low-rank adapters for parameter-efficient finetuning.
Gated recurrence enabling long-range sequence learning.
Random unit masking that became the standard regularizer.
Normalizing activations across the batch to stabilize training.
Residual connections enabling 100+ layer training.
Self-attention as the universal sequence operator.
Input–label interpolation that improved generalization.
Denoising diffusion: learn to invert a noise process.
Low-rank adapters for parameter-efficient finetuning.
MLS-Bench tests whether AI agents can invent the next ones.
Each task isolates a well-defined research question and asks the agent to propose a single modular improvement — a new loss, an attention variant, a sampler, a routing rule — then measures whether the change transfers across models, datasets, and seeds.
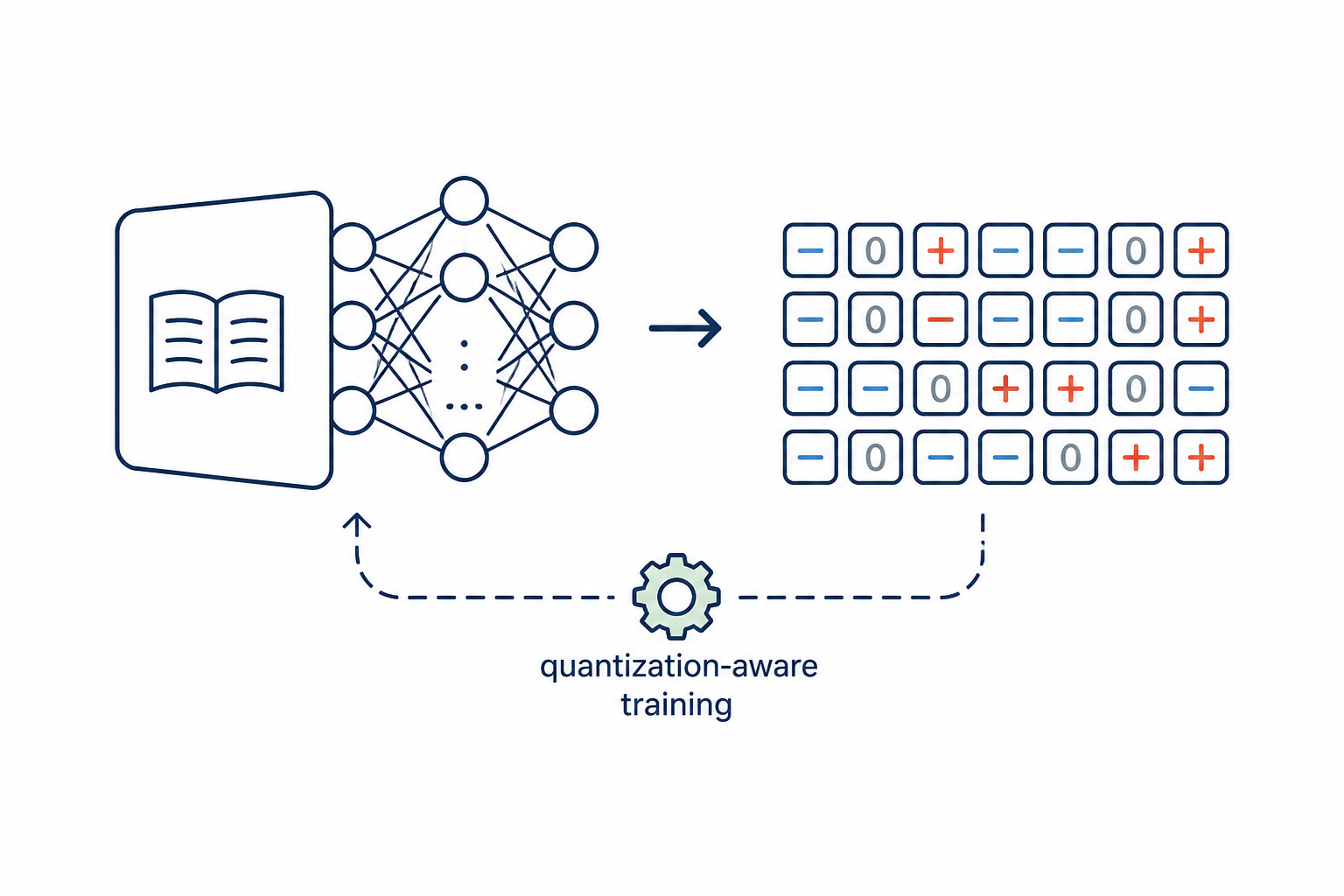 Quantization-Aware Language-Model Training
Quantization-Aware Language-Model Training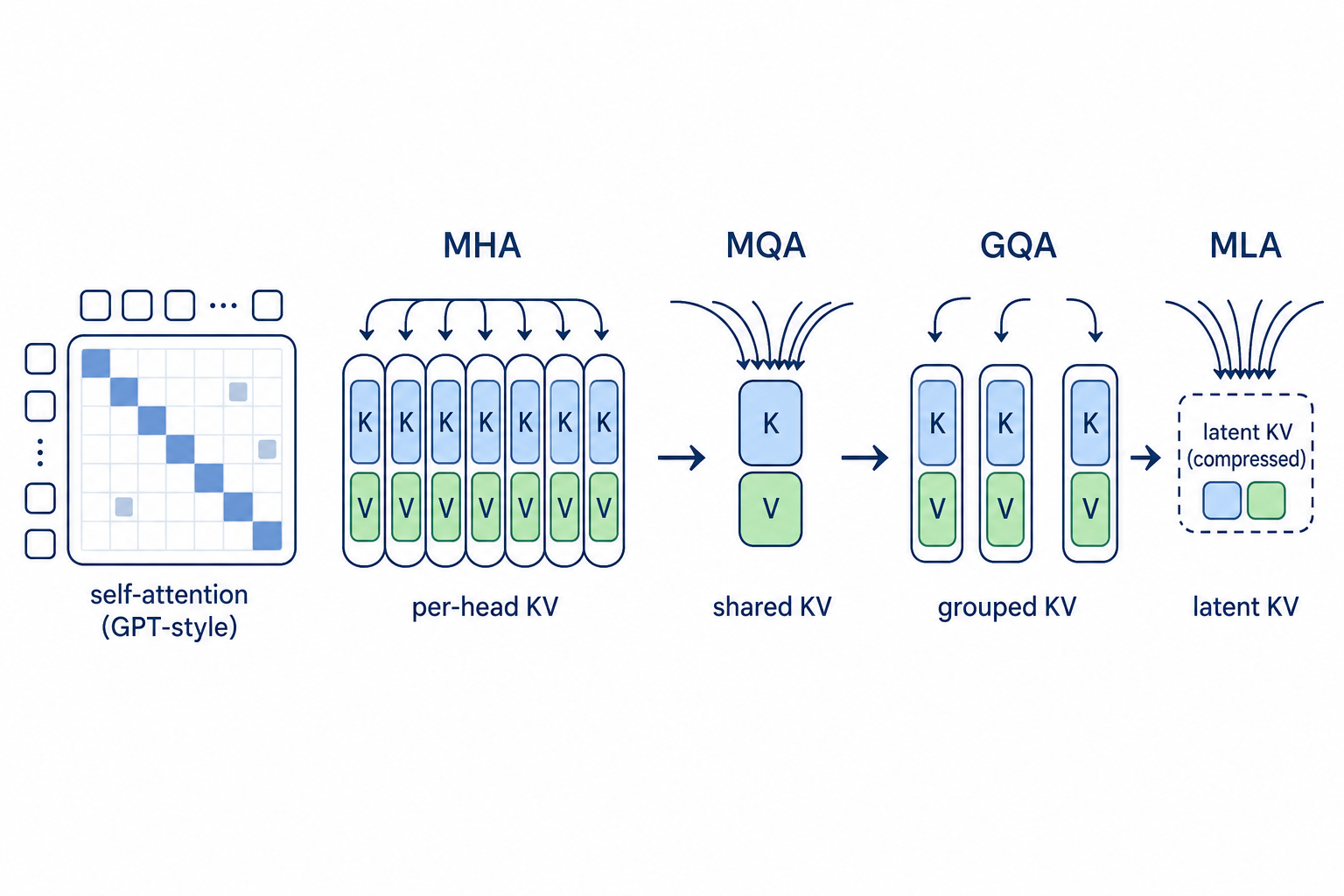 Attention Cache Structural Reduction
Attention Cache Structural Reduction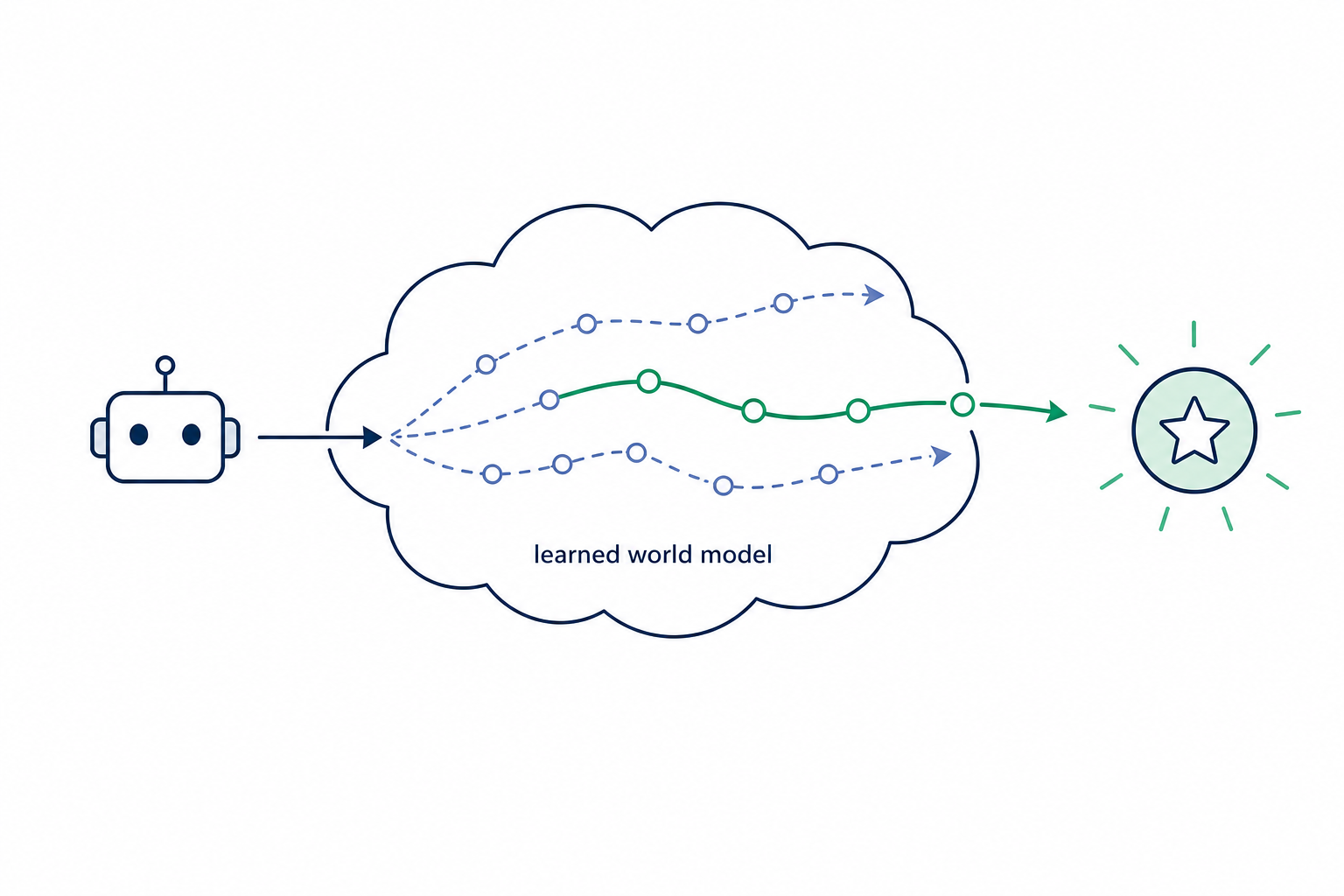 Trajectory Optimization for Model-Based Planning
Trajectory Optimization for Model-Based Planning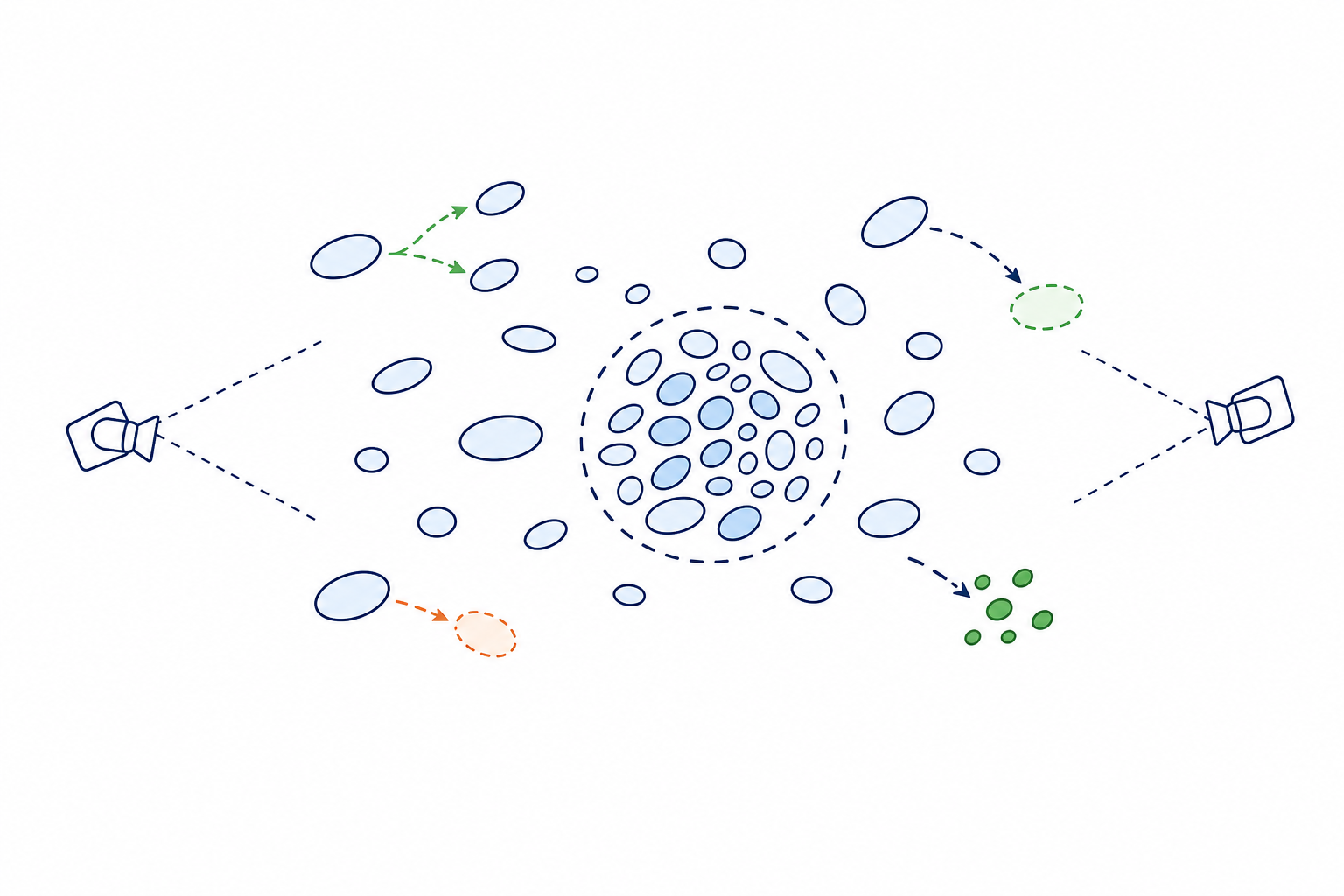 3D Scene Densification Strategy
3D Scene Densification Strategy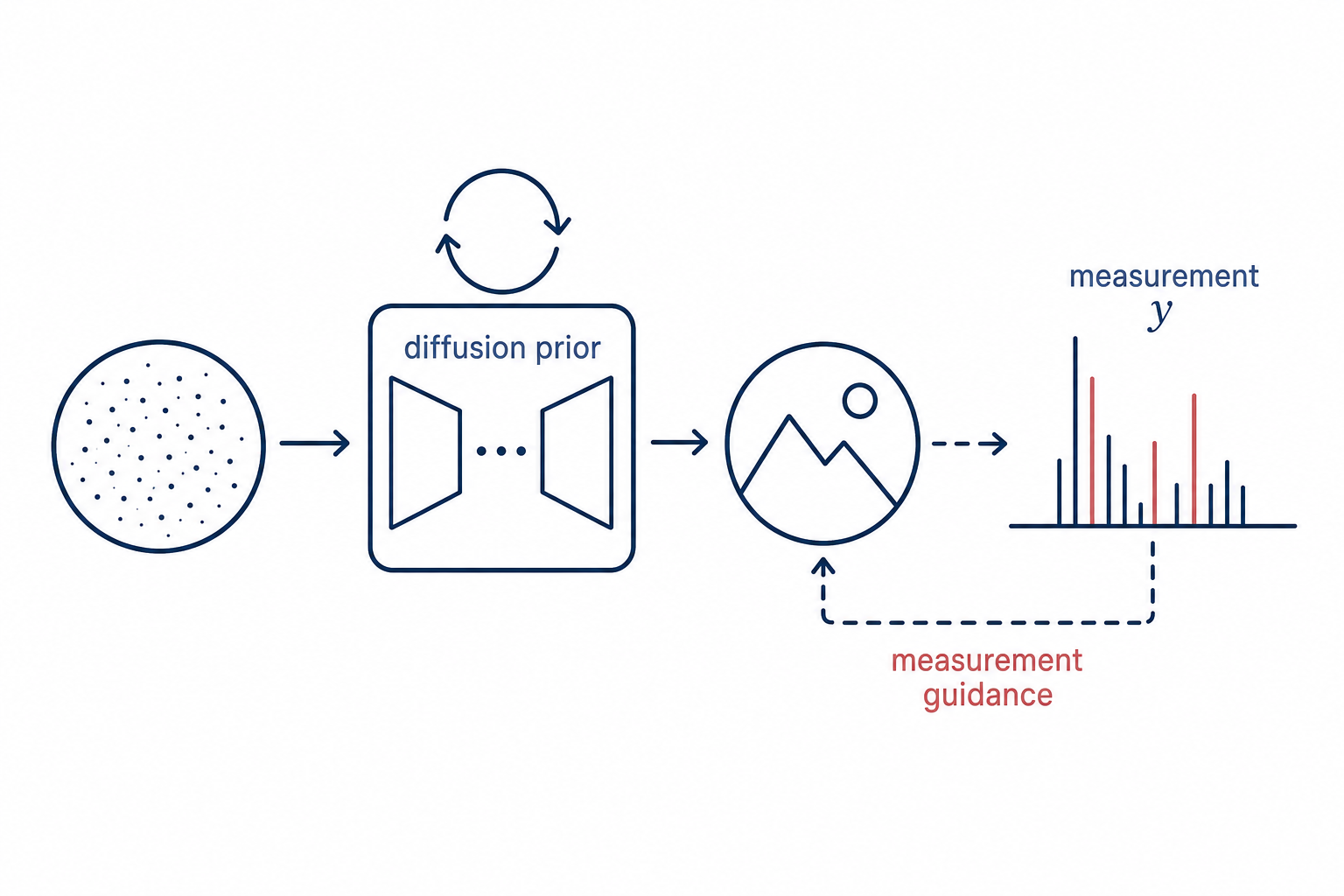 Diffusion-Prior Inverse Solver
Diffusion-Prior Inverse Solver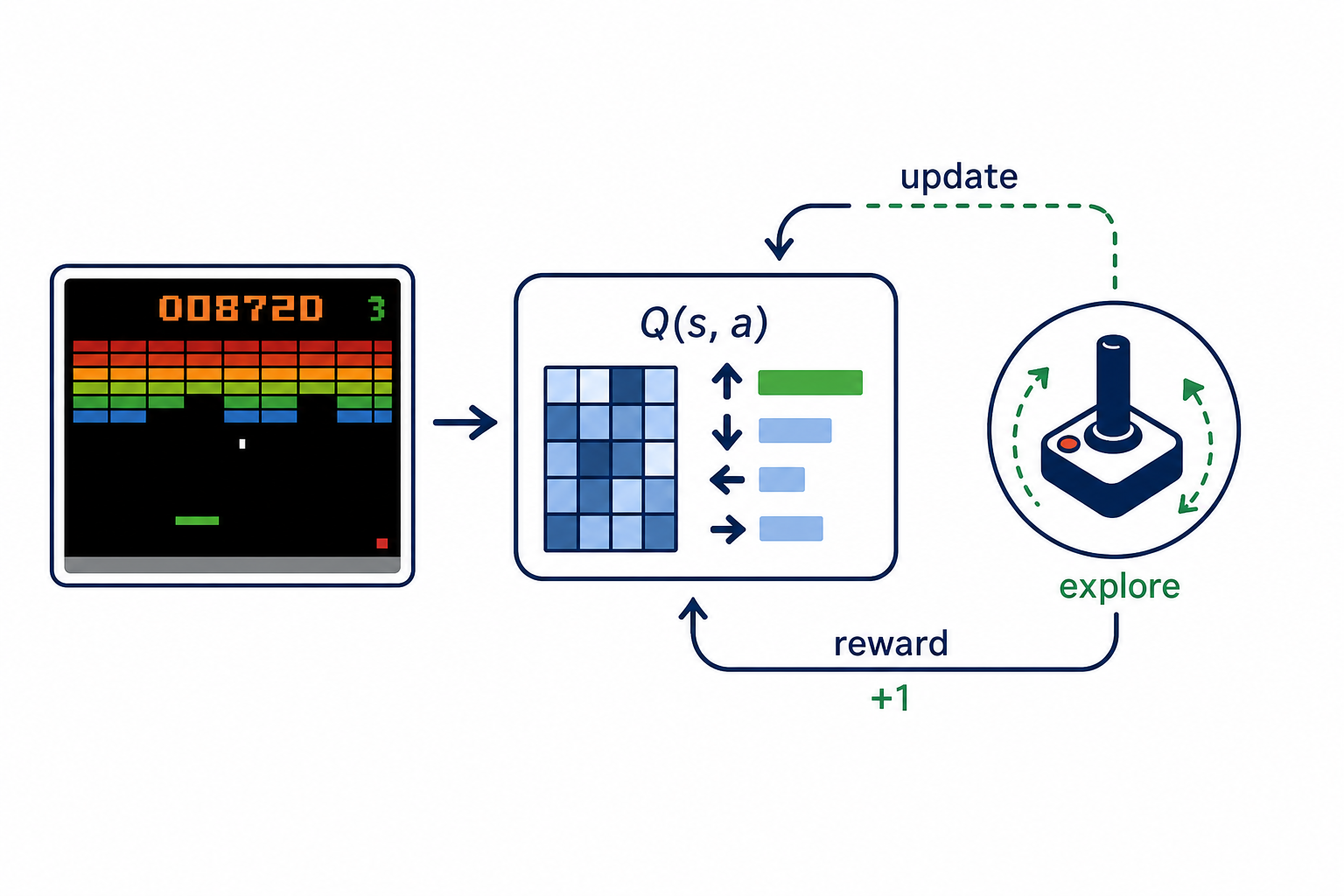 Value-Based Visual Control
Value-Based Visual Control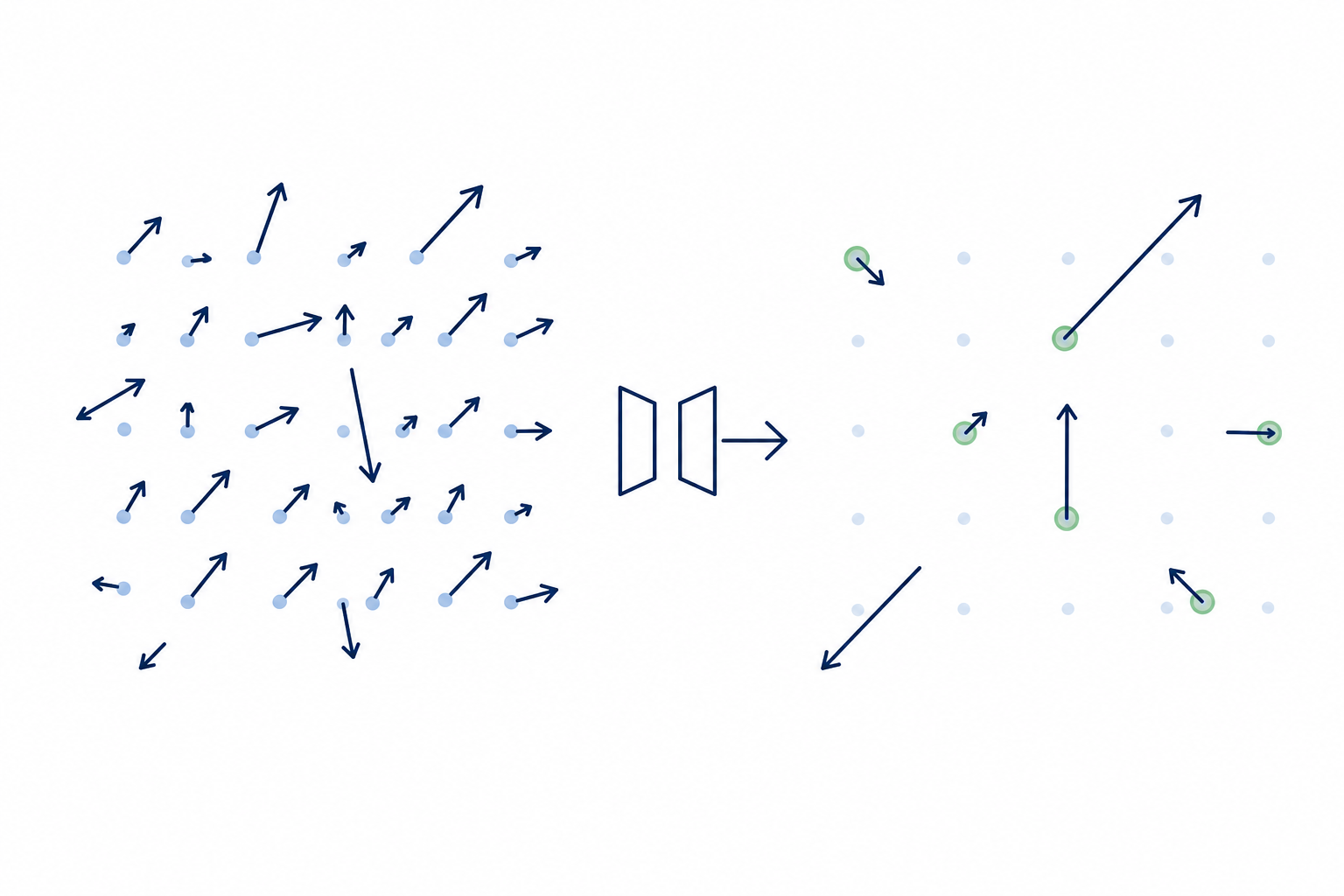 Gradient Compression for Distributed Training
Gradient Compression for Distributed Training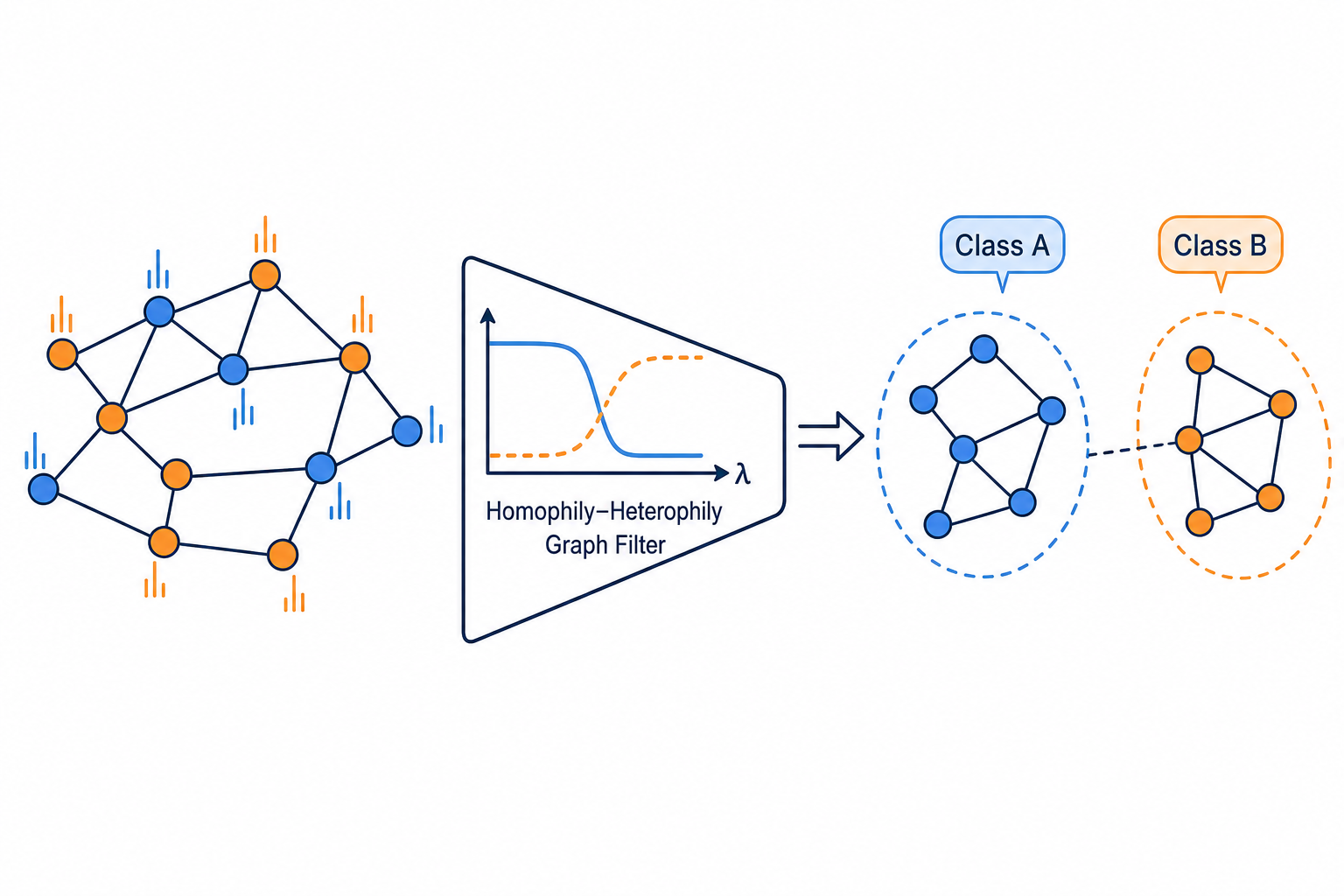 Homophily-Heterophily Graph Filter
Homophily-Heterophily Graph Filter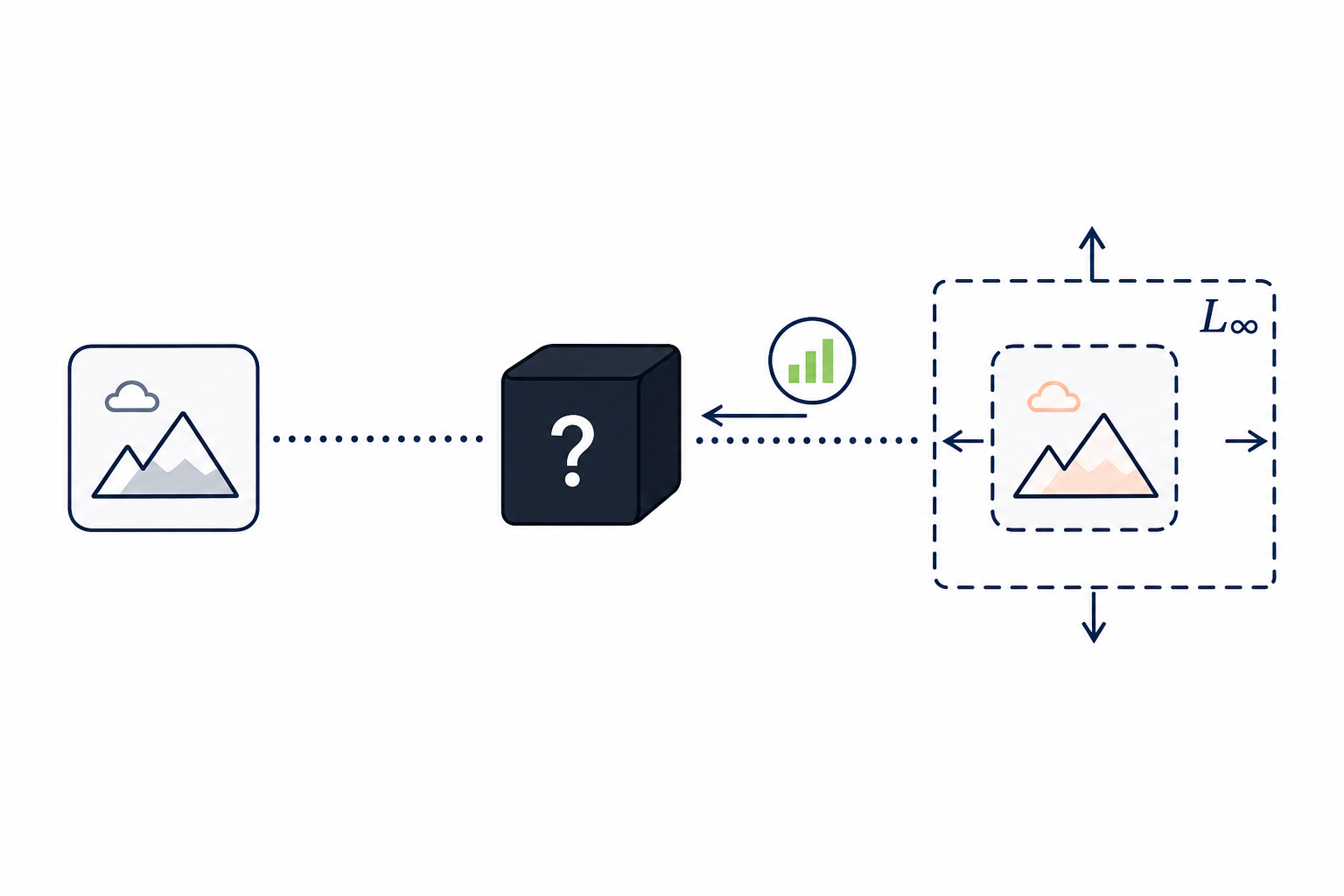 Score-Based Black-Box Linf AttackQuantization-Aware Language-Model TrainingAttention Cache Structural ReductionTrajectory Optimization for Model-Based Planning3D Scene Densification StrategyDiffusion-Prior Inverse SolverValue-Based Visual ControlGradient Compression for Distributed TrainingHomophily-Heterophily Graph FilterScore-Based Black-Box Linf Attack
Score-Based Black-Box Linf AttackQuantization-Aware Language-Model TrainingAttention Cache Structural ReductionTrajectory Optimization for Model-Based Planning3D Scene Densification StrategyDiffusion-Prior Inverse SolverValue-Based Visual ControlGradient Compression for Distributed TrainingHomophily-Heterophily Graph FilterScore-Based Black-Box Linf Attack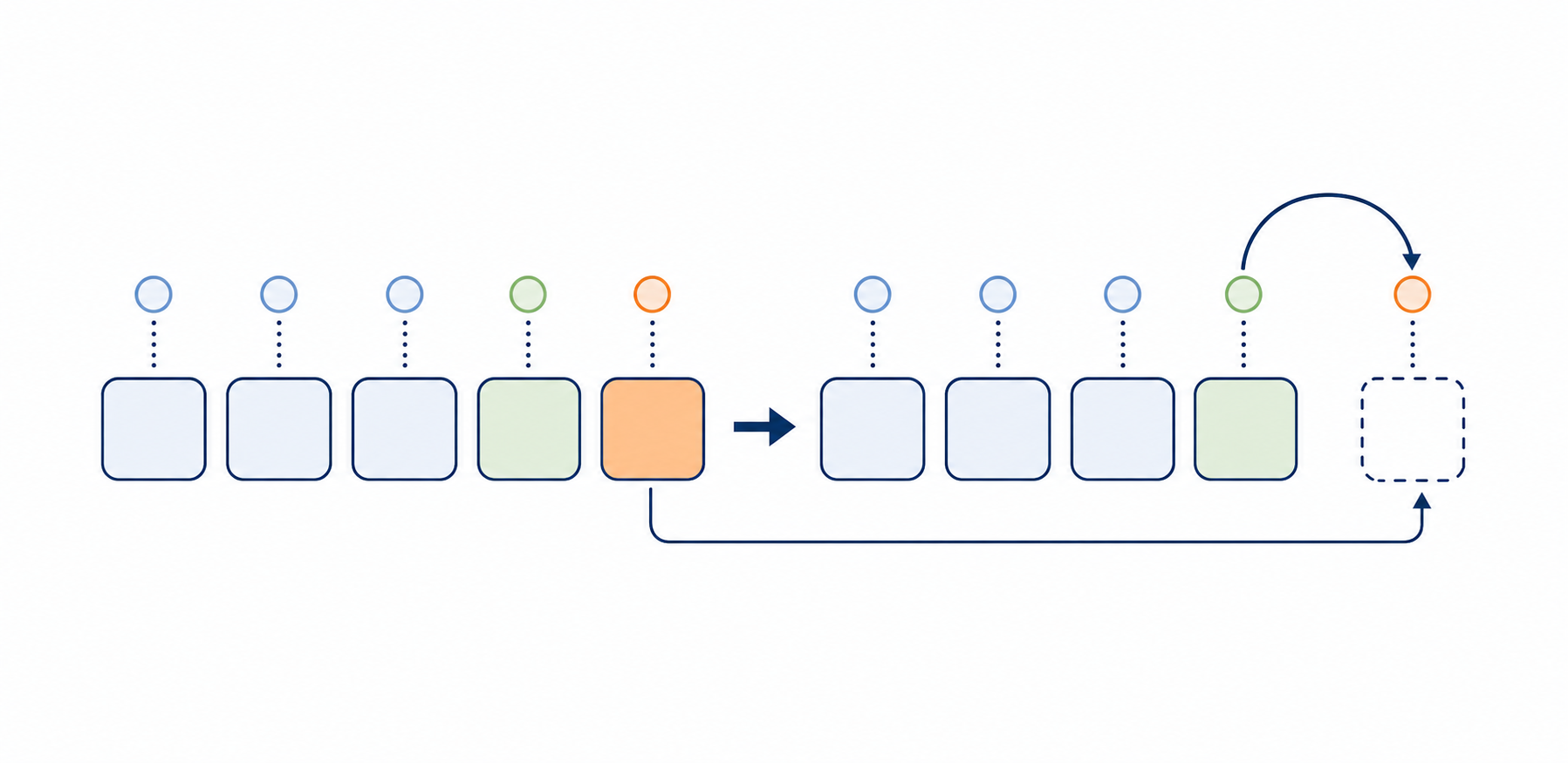 Autoregressive Embedding Strategy
Autoregressive Embedding Strategy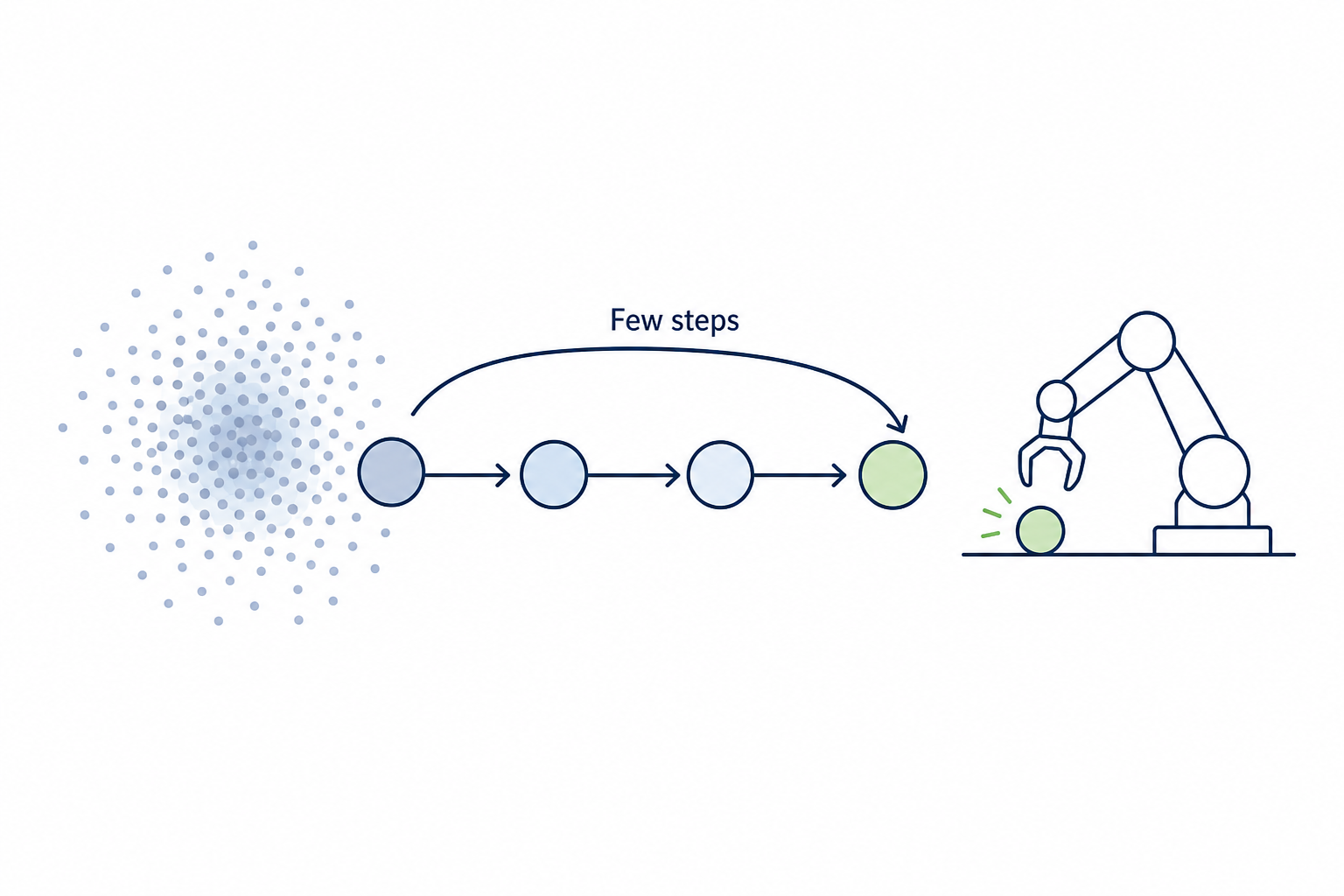 Efficient Diffusion Sampling for Robot Actions
Efficient Diffusion Sampling for Robot Actions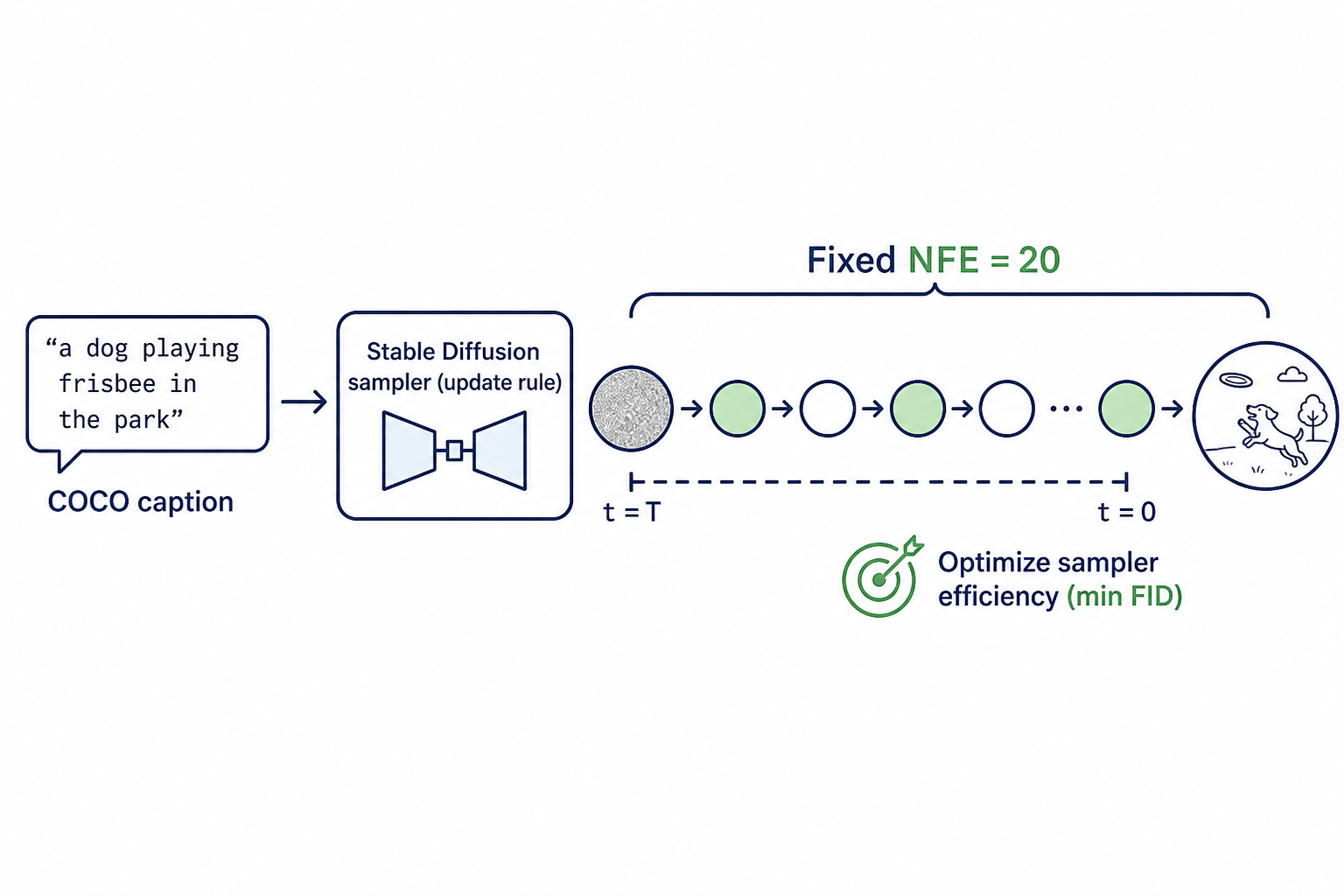 Fixed-Budget Diffusion Sampler Updates
Fixed-Budget Diffusion Sampler Updates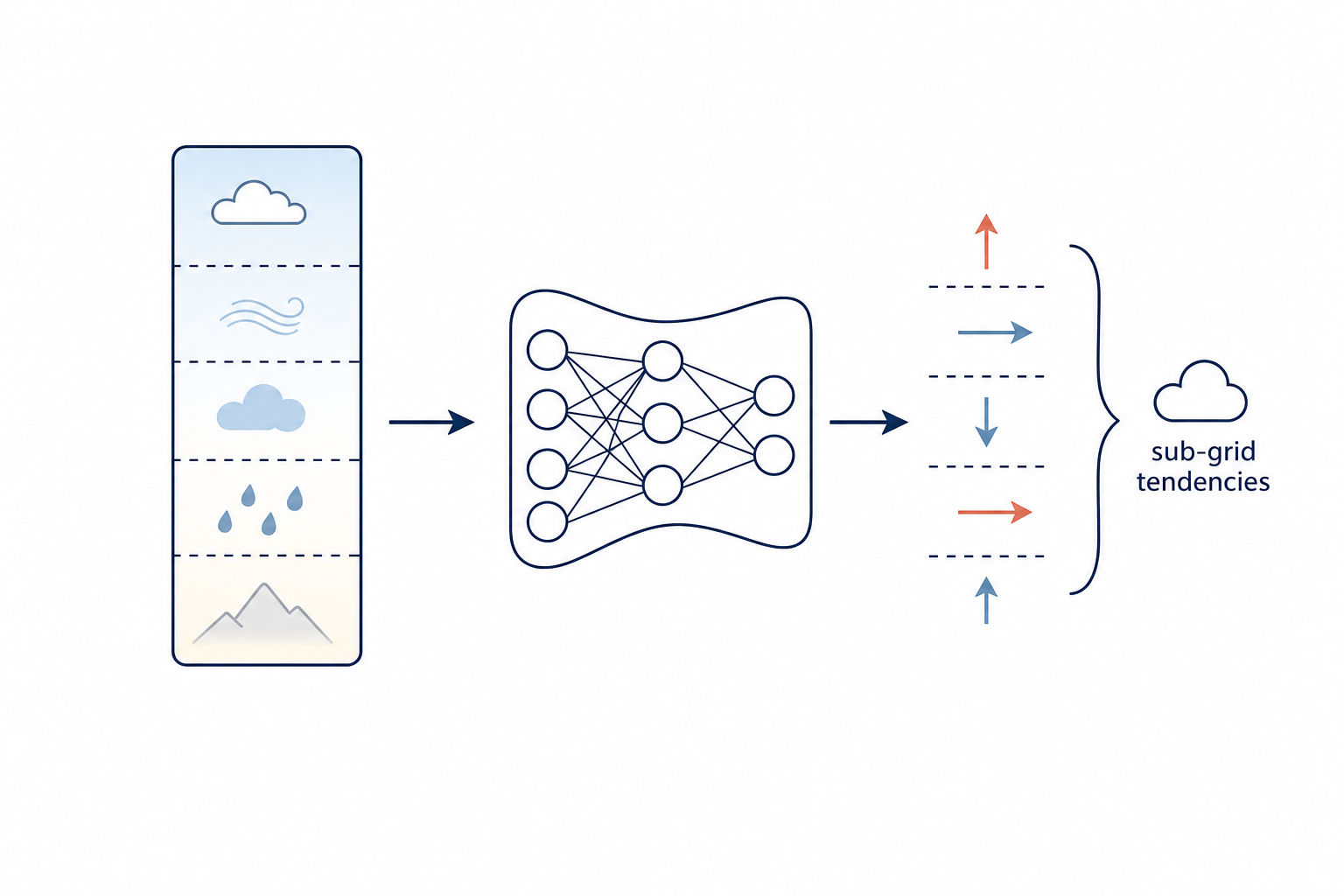 Atmospheric Column Emulator Architecture
Atmospheric Column Emulator Architecture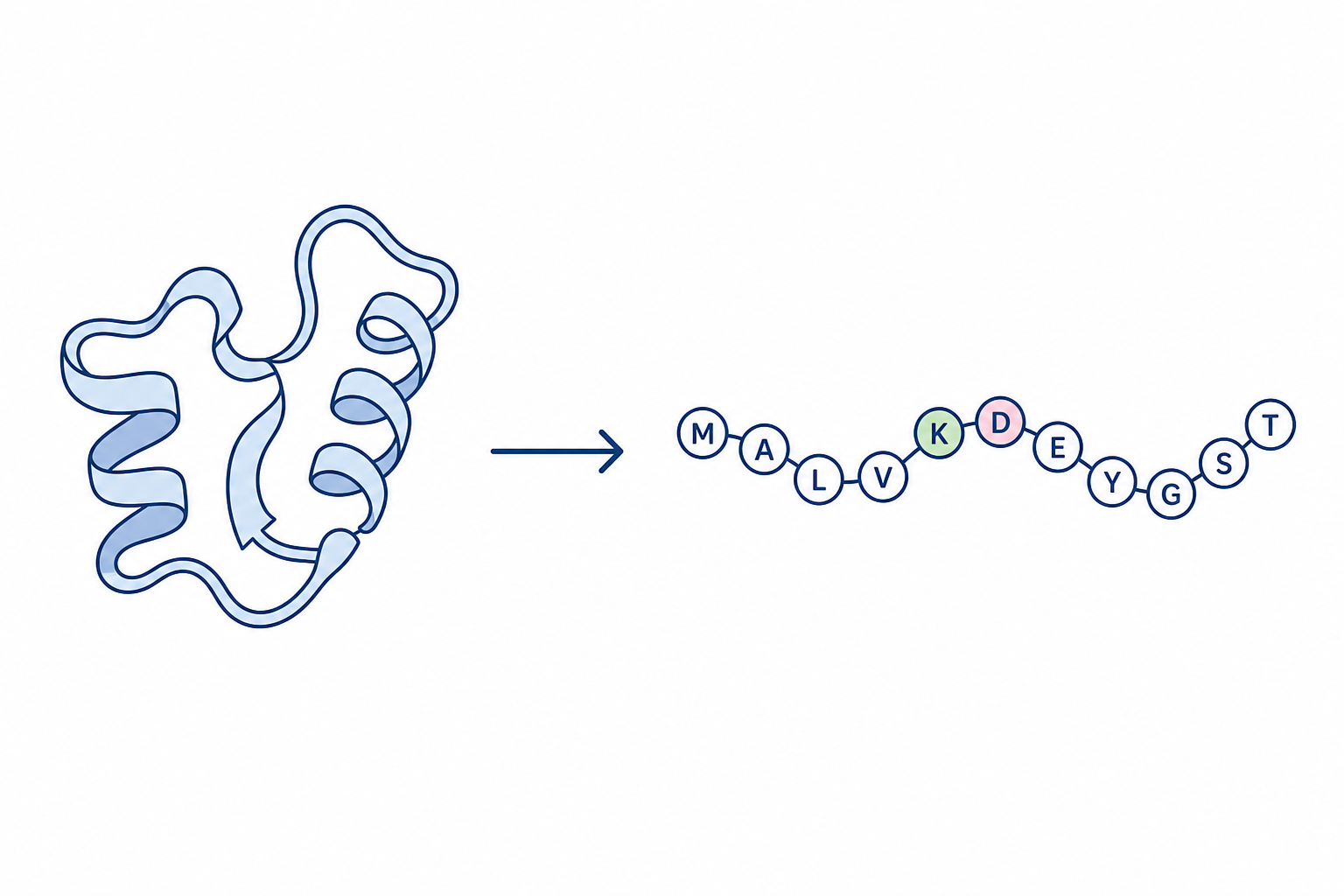 Backbone-to-Sequence Inverse Folding
Backbone-to-Sequence Inverse Folding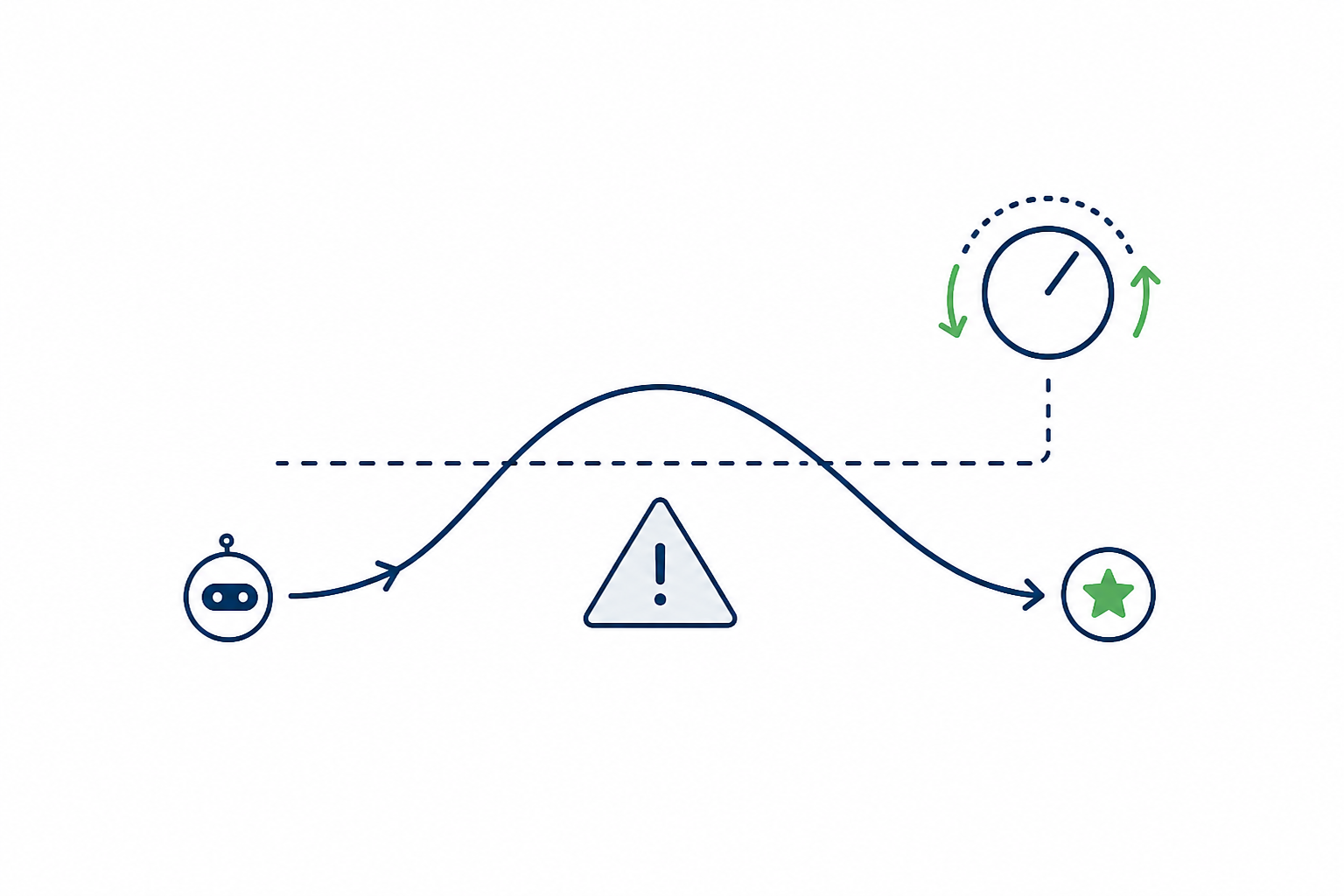 Constraint Handling for Safe RL
Constraint Handling for Safe RL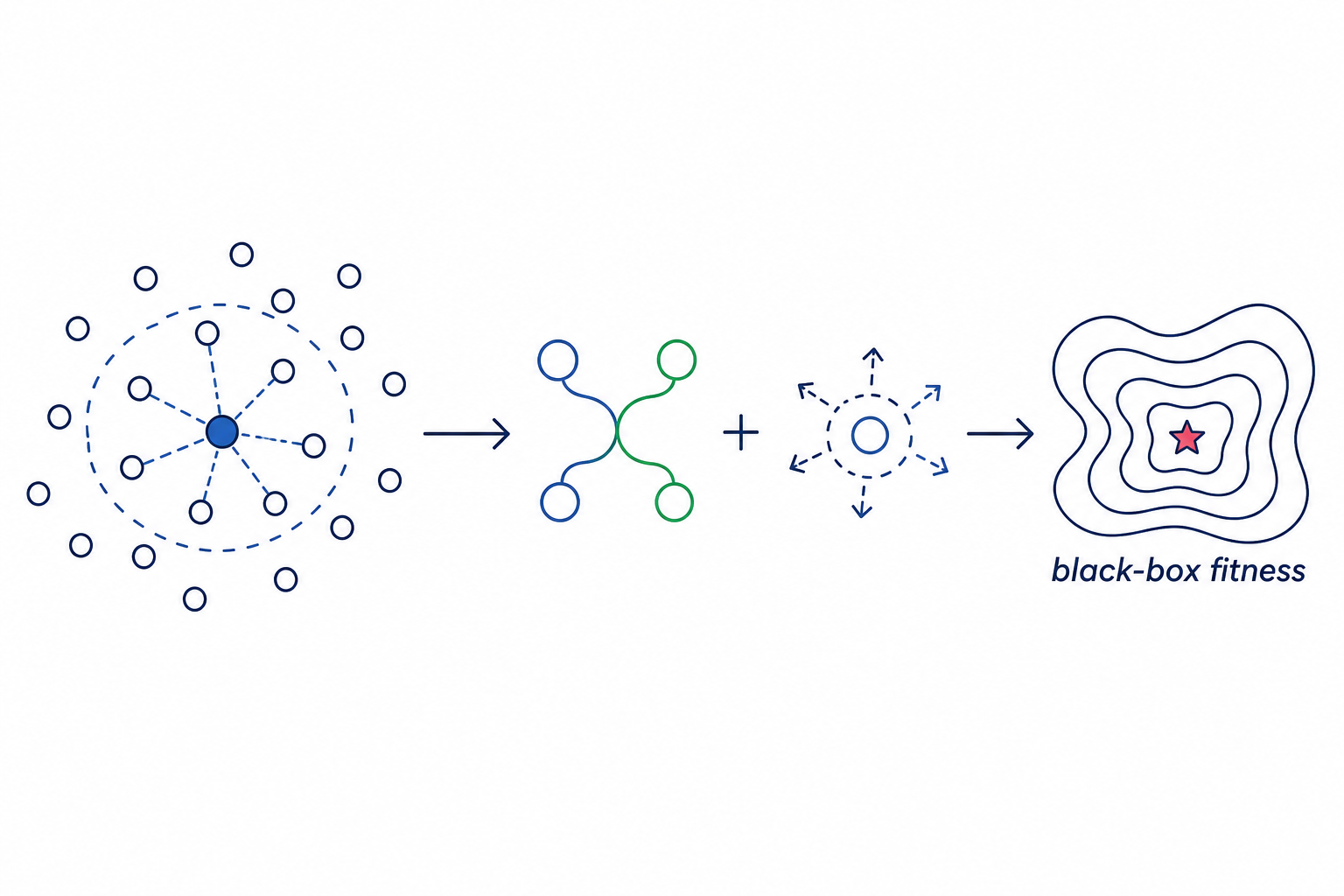 Evolutionary Operators for Continuous Black-Box Optimization
Evolutionary Operators for Continuous Black-Box Optimization Discrete Causal Graph Discovery
Discrete Causal Graph Discovery Fused Causal Attention KernelAutoregressive Embedding StrategyEfficient Diffusion Sampling for Robot ActionsFixed-Budget Diffusion Sampler UpdatesAtmospheric Column Emulator ArchitectureBackbone-to-Sequence Inverse FoldingConstraint Handling for Safe RLEvolutionary Operators for Continuous Black-Box OptimizationDiscrete Causal Graph DiscoveryFused Causal Attention Kernel
Fused Causal Attention KernelAutoregressive Embedding StrategyEfficient Diffusion Sampling for Robot ActionsFixed-Budget Diffusion Sampler UpdatesAtmospheric Column Emulator ArchitectureBackbone-to-Sequence Inverse FoldingConstraint Handling for Safe RLEvolutionary Operators for Continuous Black-Box OptimizationDiscrete Causal Graph DiscoveryFused Causal Attention Kernel140 executable tasks across 12 domains, each built around a targeted ML component, a controlled edit surface, and multi-setting evidence for transfer.
MLS-Bench-Lite Leaderboard
Scores on the official 30-task Lite subset, across harnesses and effort settings.
Model Performance by Category
Each model’s bar shows Vanilla as the darker lower portion and Agent as the lighter overlay, against a translucent grey Human SOTA reference computed from the reproduced human baselines. Scores use the paper’s normalized task metric.
Task Categories
140 tasks across 12 flat categories. Open a category to browse its tasks.