Value-Based Visual Control
Studies how value-based RL losses, update rules, and exploration strategies affect visual-control episodic return.
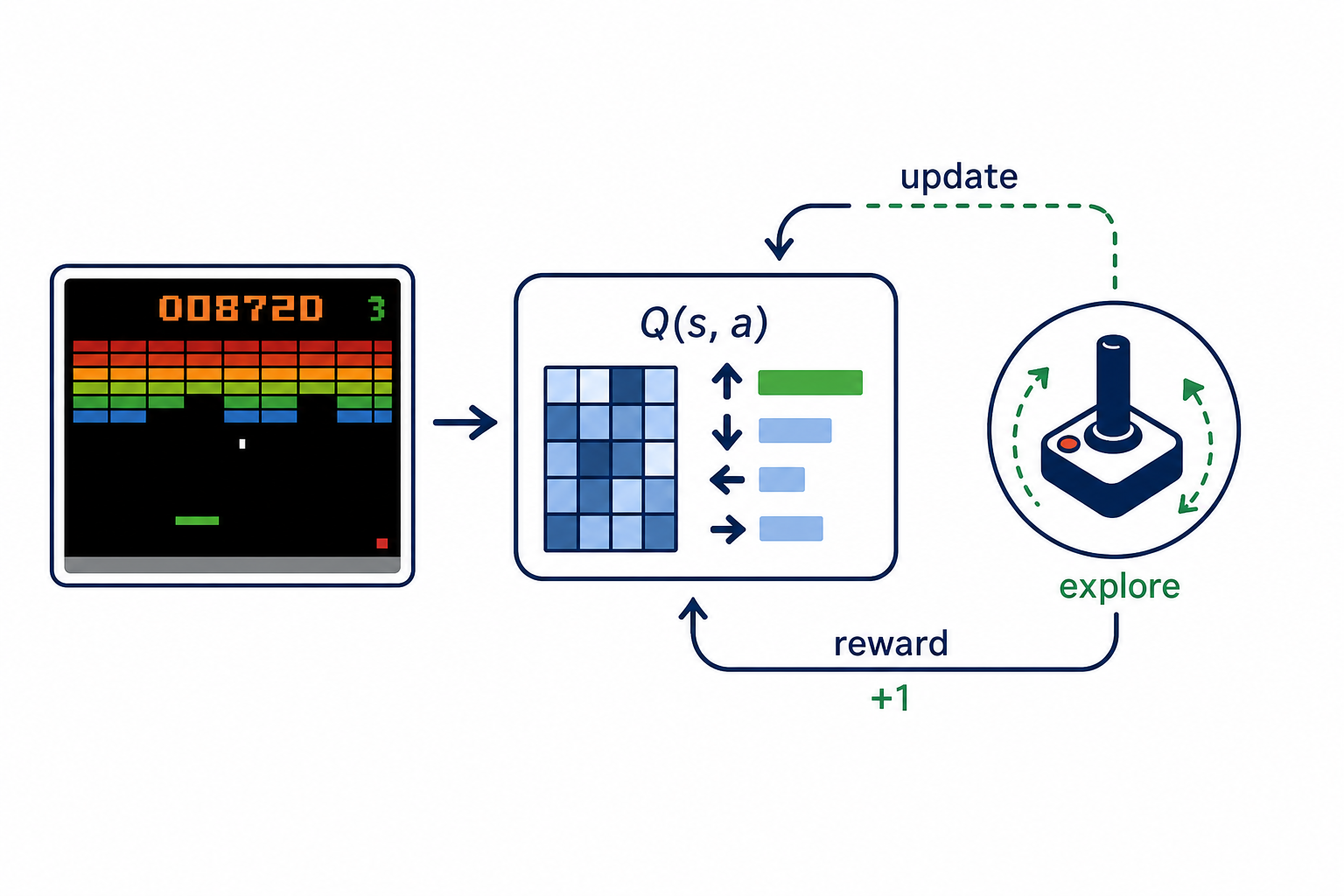
Description
Online RL: Value-Based Methods for Visual Control (Atari)
Research Question
Design and implement a value-based RL algorithm for visual / Atari
environments using CNN feature extraction. Your code goes in
custom_value_atari.py. Several reference implementations are provided
as read-only *.edit.py baselines.
Background
Atari games require learning from raw pixel observations (84x84 grayscale, 4 stacked frames). Value-based methods must learn an effective visual representation alongside Q-value estimation, handle high-dimensional observations, deal with sparse / delayed rewards, and use experience replay efficiently. Different design points address these via double targets, dueling decomposition, distributional value functions, or quantile critics.
Reference baselines spanning the design space:
- QR-DQN — Dabney et al., "Distributional Reinforcement Learning with Quantile Regression" (arXiv:1710.10044, AAAI 2018). Quantile-regression distributional critic with default 200 quantiles trained with the Huber quantile loss.
- C51 — Bellemare, Dabney and Munos, "A Distributional Perspective
on Reinforcement Learning" (arXiv:1707.06887, ICML 2017). Categorical
distributional value function with default 51 atoms over
[-10, 10]. - Double DQN — van Hasselt, Guez and Silver, "Deep Reinforcement Learning with Double Q-learning" (arXiv:1509.06461, AAAI 2016). Decouples action selection from action evaluation in the TD target.
Constraints
- Network architecture dimensions are FIXED and cannot be modified.
- Total parameter count is enforced at runtime; the contribution must be algorithmic (head design, target construction, TD loss, exploration, replay usage) rather than capacity.
- Do not simply copy a reference implementation with minor changes.
Evaluation
Trained and evaluated on multiple Atari games including Breakout, Pong and BeamRider within a fixed interaction budget using the benchmark Atari wrappers. Metric: mean episodic return over evaluation episodes (higher is better). Strong methods should improve across games rather than tuning to a single title.
Code
1# Custom value-based RL algorithm for Atari -- MLS-Bench2#3# EDITABLE section: QNetwork head and ValueAlgorithm classes.4# FIXED sections: everything else (config, env, buffer, encoder, eval, training loop).5import os6import random7import time8from dataclasses import dataclass910import gymnasium as gym11import numpy as np12import torch13import torch.nn as nn14import torch.nn.functional as F15import torch.optim as optim
Method Summary
QR-DQN + Non-crossing penalty
QR-DQN with standard target-net argmax targets and a soft penalty on quantile crossing across all actions.