MLS-Bench Paper Notes
Can AI Systems Build Better AI?
MLS-Bench asks whether an agent can make a reusable machine-learning science contribution: a new component, objective, optimizer, or training procedure that is scalable and generalizable.
Most agent benchmarks reward engineering around one fixed instance: clean the data, tune the pipeline, debug the run, select the model, and climb a leaderboard. Those skills matter, but they do not isolate the scientific step that changes how machine learning systems are built.
MLS-Bench targets that narrower and harder question. Each task fixes a research scaffold, gives the agent the relevant source code and strong baseline implementations, then asks for one algorithmic change inside a controlled edit surface. The submitted result has to generalize across settings, seeds, datasets, environments, or model scales.
The current result is clear: frontier agents can code and iterate, but they are still far from reliably surpassing strong human-designed methods. The gap is not just proposal quality. It is also scientific judgment: choosing what to test, spending limited compute, reading feedback, and knowing when a result supports a scalable claim.
What the Field Is Actually Working On
One direction in agent research is conspicuously crowded right now: self-evolve. Search over executable artifacts, score the outputs, keep the best ones, repeat. Almost every recent "AI discovers" headline comes out of some version of this loop. The shape is real and the wins are real — the question is what the wins have actually been wins on.
The Self-Evolve Wave Everyone Is Riding
A non-exhaustive snapshot of the systems in this cluster. Every one of them shares the same loop, and most of them cite each other in the same papers. Listed in no particular order.
Programs · kernels · circuits · math
DeepMind's tree-search code evolution, demonstrated on GPU/TPU kernels, TPU multiplier circuits, and math frontier problems.
Programs for combinatorial search
LLM-guided program search; new lower bounds on cap-set and online bin-packing.
Open-source AlphaEvolve loop
Community implementation evolving code against an executable scorer.
Test-time training runs
Adapts solvers during test time using executable feedback on open problems.
Programs · sample-efficient evolution
Self-improving program evolution focused on cheaper iteration steps.
Activation functions
Searches activation formulas and tests how well they transfer across model settings.
Execution-grounded operators
Evolves variation operators using executable feedback from candidate runs.
Autonomous research loops
Sakana's loop spans ideation, experiments, writing, and self-review on small studies.
…And What Those Wins Are Actually On
Run down the headline results from this cluster and a pattern jumps out. Pack circles in a square. Save one multiplication on 2×2 matmul. Trim a constant in an online bin-packing heuristic. Find a slightly larger cap set. Nudge a kernel or a multiplier circuit on one specific chip. They are exactly the right shape for an executable verifier — sharp, scalar, low-dimensional — and exactly the wrong shape for a claim about ML science.
AlphaEvolve · pack N in a square
Find a tighter packing of N equal circles in the unit square. Headline result: a slightly improved arrangement for n=11.
AlphaEvolve · scalar multiplications
Multiply two 2×2 matrices in fewer than 8 elementary multiplications. Strassen reached 7 in 1969; the agent matched it.
AlphaEvolve · one tile, one accelerator
Discover a faster low-level kernel for one fixed tile size on one accelerator (e.g. a FlashAttention building block).
AlphaEvolve · fixed bit-width
Search for a smaller arithmetic circuit on one chip at a fixed bit-width, scored by gate / transistor count.
FunSearch · worst-case ratio
Place arriving items into the fewest bins; tighten a small constant in the worst-case ratio of an online heuristic.
FunSearch · combinatorial bound
Find a larger subset of {0,1,2}ⁿ with no 3-term arithmetic progression. New lower bound on a single combinatorial constant.
That is the gap MLS-Bench is built for. The executable, agentic shape these systems pioneered is genuinely powerful, but applying it to circle packing or 2×2 matmul schemes is not the same thing as discovering an ML method. MLS-Bench keeps the harness and moves the target: discover a real ML-science change — a model component, objective, optimizer, or training procedure — that survives across datasets, seeds, environments, and model scales.
What MLS-Bench Measures
A task is meant to feel like a small research iteration rather than a general coding assignment. The benchmark covers 140 tasks across 12areas of ML — language models, reinforcement learning, robotics, vision and generation, ML systems, AI for science, optimization, time series, causal reasoning, trustworthy learning, classical learning, and deep learning. Hover any category below to peek at the actual tasks inside.
The key design constraint is attribution. Agents can edit the target component, but they cannot rewrite the evaluation harness, change the shared training protocol, inflate model capacity, or probe hidden settings. Baselines are implemented in the same scaffold, so a score gain is measured against methods the task can already express.
Scores are normalized per task. The weakest reproduced baseline anchors the floor, the strongest reproduced baseline anchors the human-SOTA reference, and each method is aggregated across metrics and settings. That makes cross-area comparisons possible without hiding the fact that raw metrics differ by domain.
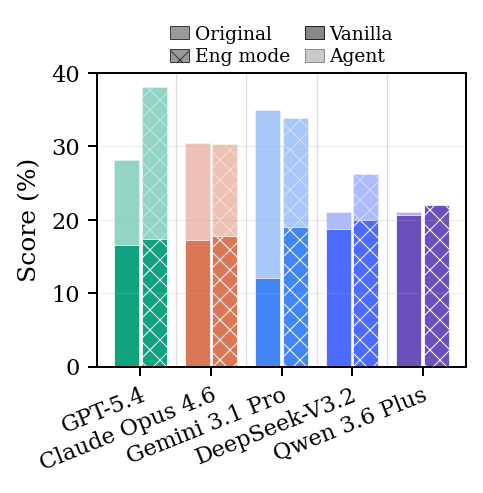
Main Result
The main experiments evaluate Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro, DeepSeek-V3.2, and Qwen 3.6 Plus on the full benchmark. Agents receive baseline implementations and can make up to three test calls before submitting a final result. The paper reports both the first proposal, called Vanilla, and the final submitted Agent result.
Iteration helps, but mostly by narrowing the gap. The agents often improve over their first attempt, yet they do not reliably reach the best reproduced human method inside the same controlled scaffold. The benchmark is therefore unsaturated in the capability it is designed to measure.
Why the Controls Matter
The ablations separate method discovery from easier ways to improve a number. When prompts invite engineering optimization, weaker agents can gain by tuning, recombining known tricks, or polishing an existing implementation. That improvement is real engineering work, but it is not the same as discovering a new method.
Capacity checks are also necessary. If the task allows a model-size increase, some agents exploit the open surface and win by making the model larger rather than by improving the algorithm. The controlled benchmark closes that route so the remaining gain is tied to the intended research axis.
Multi-setting evaluation is the other half of the control. A useful method should carry from in-domain settings to out-of-distribution ones. The benchmark tracks whether iteration improves both, rather than only fitting the cases the agent can see.
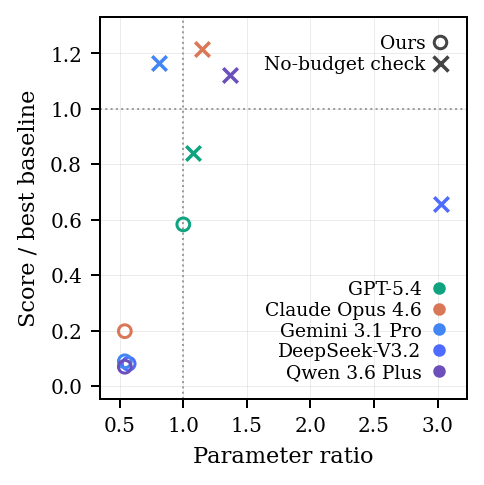
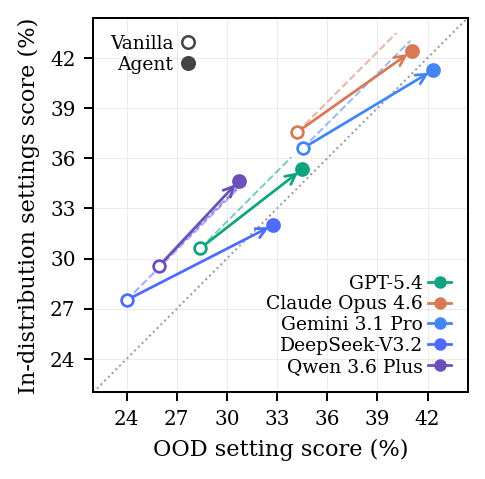
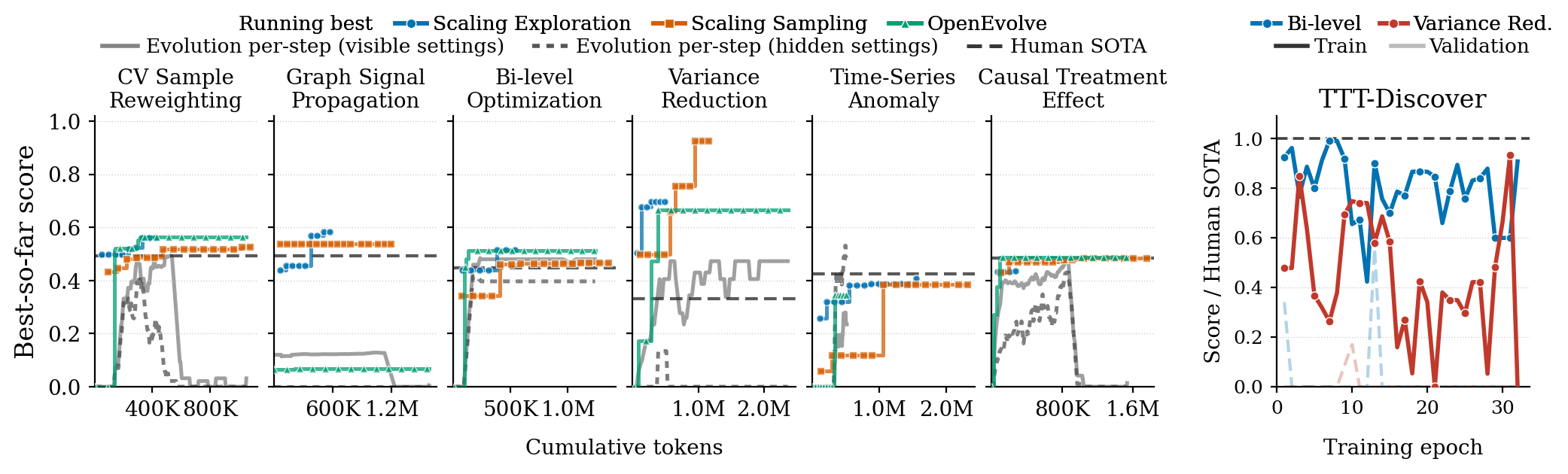
More Compute Is Not Enough
Test-time scaling improves simpler tasks for a while. Sampling more first proposals or giving the agent more exploration rounds can raise the running-best score. But the gains saturate, and harder tasks keep a ceiling below human SOTA.
Evolutionary search and test-time training expose a sharper failure mode under partial feedback. They can preserve or improve in-domain scores while damaging OOD settings. That is optimization of the observed verifier, not discovery of a method that transfers.
The Hard Part Is Evidence
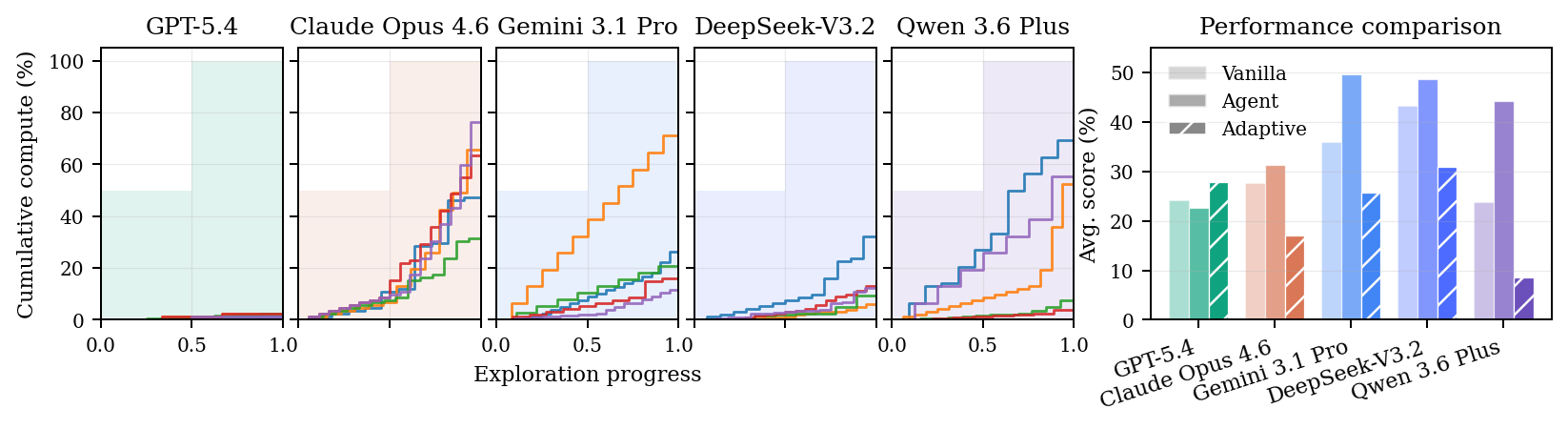
Real ML science is verifier-limited. Running a proxy experiment is not the same as establishing that a method scales. MLS-Bench simulates this pressure in an adaptive compute-allocation experiment for LLM pretraining tasks: agents choose model sizes, token budgets, and how to spend limited trials.
More freedom does not automatically help. Most agents perform worse under the adaptive protocol than under the simpler fixed one. This points to a capability gap beyond method proposal: current systems struggle to plan informative experiments and convert feedback into reliable evidence.
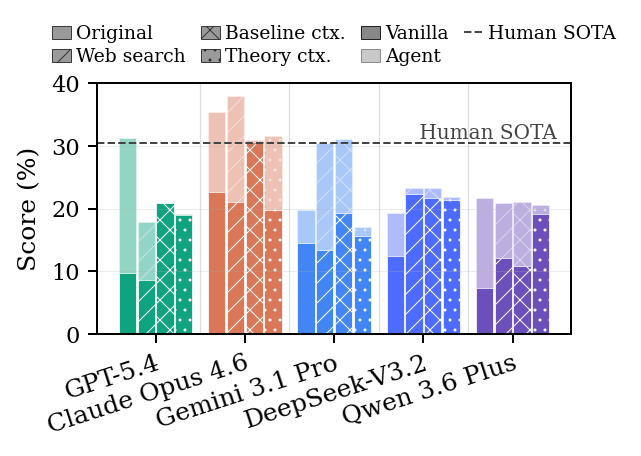
Context Helps Less Than Expected
Extra context can help a strong model, but it does not remove the main bottleneck. Web search, detailed baseline explanations, and theory background produce modest gains, often comparable to ordinary iterative refinement.
The failure is not simply missing knowledge. The harder step is turning context into a hypothesis that is relevant to the scaffold, implementable in the allowed edit surface, and robust across settings.
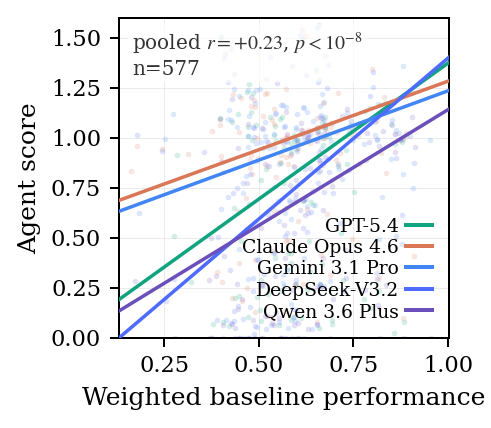
What Agents Actually Do
Expert assessment finds a recurring pattern. Agents often recombine ingredients from the baseline implementations they are shown and present the recombination as a new method. Truly new mechanisms are rarer, and when they appear, the justification for why they should work is often thin.
Code-similarity analysis supports the same diagnosis. For weaker models, performance is strongly tied to resemblance to high-scoring baselines. That is useful signal: copying the shape of a strong method is a reasonable fallback, but it is not the capability MLS-Bench is meant to celebrate.
Where This Leaves the Benchmark
MLS-Bench is a measurement tool for a specific gap: turning an idea into a reusable machine-learning method. Stronger models, better agent harnesses, and self-improving discovery systems should move the leaderboard, but the target remains the same: improve the method, keep the evaluation fair, and show that the gain survives beyond the first setting.
The gap we measure is wider than just proposing methods. It extends to turning an idea into evidence: deciding what to test, how to spend limited trials, and when a result supports a scalable claim. Today's agents look even weaker at this evidence-building process than at method proposal itself — a sign that better search alone is not scientific discovery. Real discovery requires forming questions, learning from trials, allocating time and compute, and turning experiments into transferable claims. MLS-Bench is built to make that distinction measurable.
Limitations and What We're Building Next
MLS-Bench is only a first step. ML science is too broad and fast-moving for one benchmark to exhaust, and the trade-off between rigor and freedom is one we will keep tuning. We are actively expanding the task catalog toward more open-ended research questions, refining evaluation protocols so they stay rigorous as the freedom we give agents grows, and tightening the tooling around evidence-building so the benchmark continues to measure scientific judgment, not just method search.
If you would like to contribute — new tasks, evaluation ideas, baselines, or analyses — please reach out: Bohan Lyu (bohan@berkeley.edu).
Continue with the task catalog on the Tasks page, or open the GitHub repository for the executable benchmark.
Citation
@misc{lyu2026mlsbenchholisticrigorousassessment,
title={MLS-Bench: A Holistic and Rigorous Assessment of AI Systems on Building Better AI},
author={Bohan Lyu and Yucheng Yang and Siqiao Huang and Jiaru Zhang and Qixin Xu and Xinghan Li and Xinyang Han and Yicheng Zhang and Huaqing Zhang and Runhan Huang and Kaicheng Yang and Zitao Chen and Wentao Guo and Junlin Yang and Xinyue Ai and Wenhao Chai and Yadi Cao and Ziran Yang and Kun Wang and Dapeng Jiang and Huan-ang Gao and Shange Tang and Chengshuai Shi and Simon S. Du and Max Simchowitz and Jiantao Jiao and Dawn Song and Chi Jin},
year={2026},
eprint={2605.08678},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2605.08678},
}