Attention Cache Structural Reduction
Studies how head sharing and latent compression reduce attention-cache memory while preserving pretraining quality.
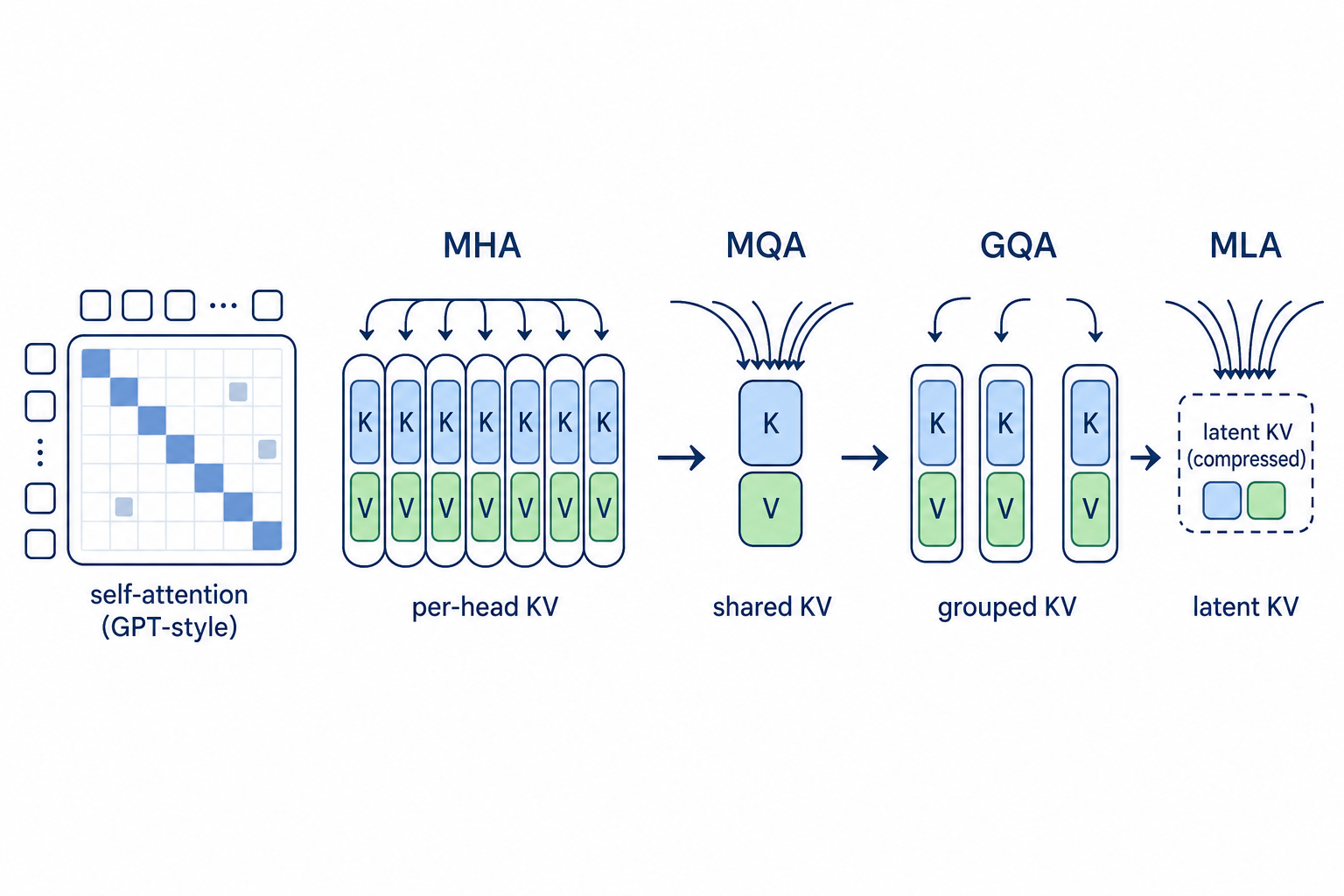
Description
LLM Pretraining: KV-Structural Reduction
Research Question
Design a more KV-efficient causal attention structure for GPT-style pretraining, with the primary focus on the tradeoff between KV head sharing and latent KV compression:
- how much language-model quality can be preserved by reducing the realized KV state
- whether grouped/shared KV heads or latent KV bottlenecks give the better quality-memory tradeoff under a fixed small-scale pretraining budget
Background
Multi-Head Attention (MHA) materializes one (K, V) pair per query head, which dominates KV memory at long context. Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) reduce that by sharing a small number of K/V heads across many query heads. Multi-head Latent Attention (MLA), proposed in DeepSeek-V2 (Liu et al., 2024; arXiv:2405.04434) and analyzed further in TransMLA (Meng et al., 2025; arXiv:2502.07864), instead compresses K/V into a low-rank latent vector that is decompressed on the fly, decoupling realized KV bytes from query-head count. This task isolates that design space inside one fixed nanoGPT-style pretraining loop.
What You Can Modify
One editable region in custom_pretrain.py:
- Attention-structure region (between read-only
# BEGIN/END KV EDITABLE REGIONmarkers — do NOT delete or replace the marker lines), including:build_kv_heads(...): how many KV heads are materialized relative to query headscross_layer_share(...): optional structural sharing hook inside the attention stacklatent_kv_project(...): whether K/V are compressed into a lower-rank latent spaceCausalSelfAttention: how the above choices are instantiated inside the attention block, including the internal query/KV projection and attention mixing path
Intended Task Boundary
- This task studies KV-state reduction inside the attention block.
- The main comparison axes are dense MHA vs grouped/shared KV heads, and grouped/shared KV heads vs latent KV compression.
cross_layer_share(...)remains available as an auxiliary structural hook inside the same block.- The evaluator enforces the top-level boundary of this region with an AST
validator: only the allowed helper functions plus
CausalSelfAttentionmay appear in the editable span. That keeps edits inside the attention block, even though the internal contents ofCausalSelfAttentionremain flexible.
Evaluation
Evaluation follows the same setup as other llm-pretrain-* tasks: primary
evaluation at 345M scale (24L/16H/1024D) with downstream lm-eval. The KV
footprint and throughput diagnostics specific to this task are measured
from the 345M checkpoint.
- Primary metric: validation loss at 345M (cross-entropy, lower is better)
- Secondary metrics:
kv_bytes_per_token(lower is better; evaluator-derived KV footprint from the realized attention structure — the primary efficiency axis)heldout_loss(lower is better; average cross-entropy on WikiText-2/103 + LAMBADA held-out corpora at the 345M final checkpoint)arc_easy,hellaswag(0-shot downstream accuracy via lm-eval, from the 345M checkpoint)
- Visible benchmark regimes:
gpt-345m: 345M pretraining on ClimbMix with KV structural metrics + held-out evallm-eval-345m: 0-shot downstream evaluation (ARC-Easy, HellaSwag, PIQA, Winogrande)
- Training data: ClimbMix tokenized training split (~58GB)
- Held-out eval data: WikiText-2, WikiText-103, LAMBADA (packaged
evaldependency) - Training schedule: 345M uses Chinchilla-optimal ~7.1B tokens (13535
steps, 2-GPU DDP, LR=3e-4, same as
llm-pretrain-attention)
Baselines
The visible baseline chain is MHA -> MQA -> GQA -> MLA:
MHA: dense unreduced control with one KV head per query head.MQA: simplest structural anchor with one shared KV head reused across all query heads.GQA: keeps full query heads but reduces the number of materialized KV heads.MLA: latent-KV bottleneck adapted from the DeepSeek-V2 (arXiv:2405.04434) / TransMLA (arXiv:2502.07864) family into the fixed nanoGPT substrate. A proper MLA implementation haskv_lora_rank < head_dimso thatkv_bytes_per_token < 256(beating MQA on the same evaluation).
Code
1"""Custom GPT-2 pretraining script for KV-structural reduction tasks.23Based on Andrej Karpathy's nanoGPT, with a narrow editable region for KV4structure changes such as grouped KV heads and latent KV compression.5"""67import ast8import inspect9import json10import math11import os12import time13from contextlib import nullcontext14from dataclasses import dataclass15
Method Summary
GLA-DPV: 2-group MLA + dual-path V
MLA with two independent KV latent groups and a per-head sigmoid-gated dual value path mixing the standard up-projection with a direct latent-to-value projection.