Fixed-Budget Diffusion Sampler Updates
Studies how latent diffusion sampling updates improve text-image alignment under a fixed inference-step budget.
Description
Diffusion Model: Sampler Efficiency Optimization
Objective
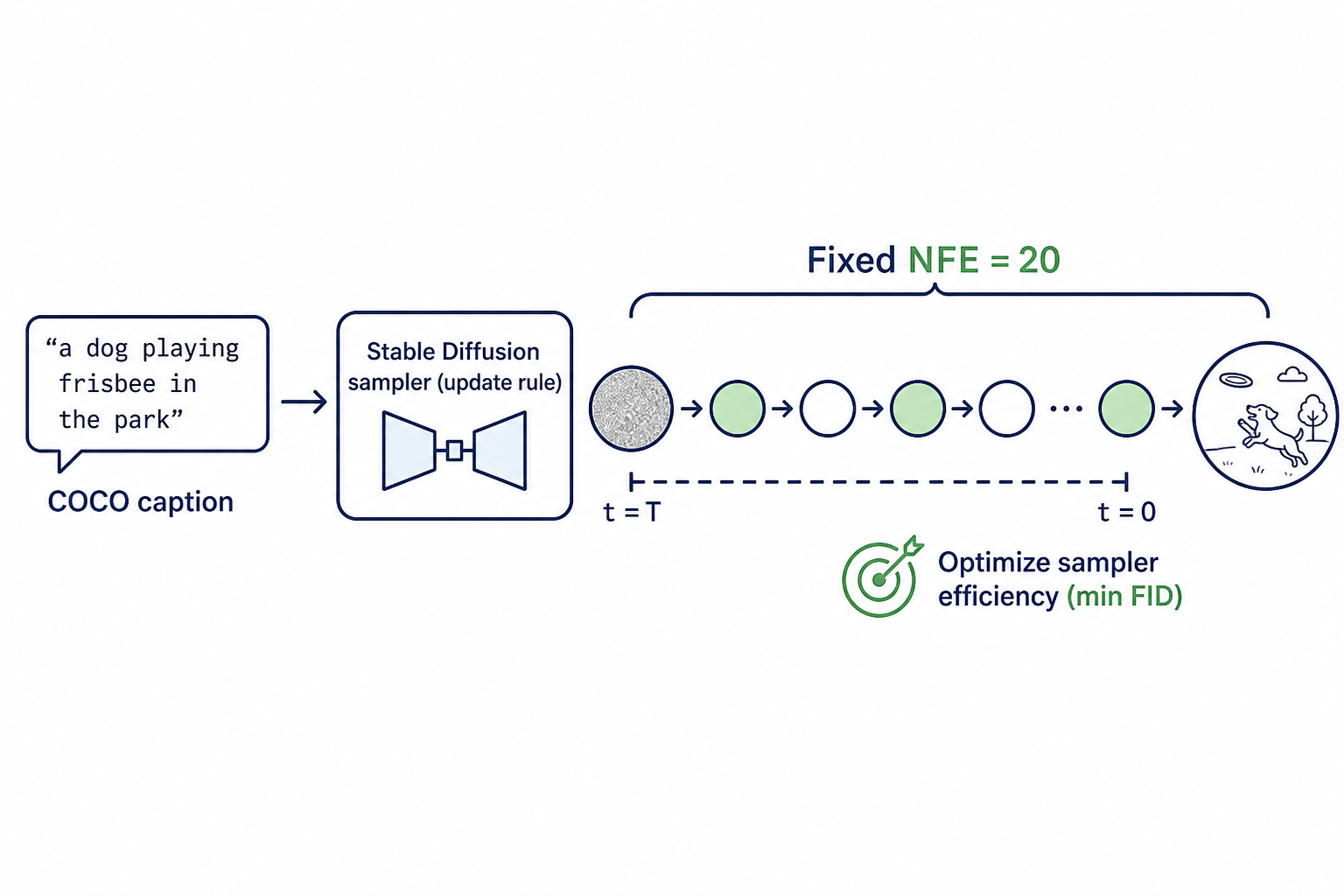
Design a sampling algorithm for text-to-image diffusion models that achieves high generation quality with a fixed budget of NFE = 20 denoiser evaluations.
Background
Diffusion models generate images by iteratively denoising from random noise. Different samplers differ in how they update the latent after each model prediction. The general structure of one step is:
for step, t in enumerate(timesteps):
# 1. Predict noise.
noise_pred = model(zt, t, text_embedding)
# 2. Estimate clean image (Tweedie's formula).
z0t = (zt - sigma_t * noise_pred) / alpha_t
# 3. Update to next step (this differs across samplers).
zt_next = update_rule(zt, z0t, noise_pred, t, t_next)Reference families:
- DDIM (Song et al., ICLR 2021, arXiv:2010.02502) — first-order ODE solver, deterministic, simple update rule.
- DPM-Solver++ (Lu et al., 2022, arXiv:2211.01095) — high-order solvers
for the diffusion ODE in data-prediction form.
- DPM-Solver++(2M) — second-order multistep variant, reuses the previous denoiser output.
- DPM-Solver++(2S) — second-order singlestep variant, smaller high-order error constant.
- DPM-Solver++(3M) SDE — third-order multistep stochastic variant for guided sampling.
A useful method may use time-dependent coefficients, history (multistep), predictor-corrector structure, or guidance-aware renoising — but it must respect the fixed function-evaluation budget.
Implementation Contract
Implement the update rule for both Stable Diffusion v1.5 and SDXL by editing the marked editable regions of two files:
latent_diffusion.py—BaseDDIMCFGppclass for SD v1.5 (sample()method). Available helpers:self.get_text_embed(),self.initialize_latent(),self.predict_noise(),self.alpha(t).latent_sdxl.py—BaseDDIMCFGppclass for SDXL (reverse_process()method). Available helpers:self.initialize_latent(size=...),self.predict_noise(),self.scheduler.alphas_cumprod[t].
The contribution must respect a fixed budget of NFE = 20 denoiser calls per sample.
Baselines
| Baseline | Description |
|---|---|
ddim | DDIM (Song et al., ICLR 2021, arXiv:2010.02502). First-order deterministic. |
dpm3m_sde | DPM-Solver++(3M) SDE multistep variant (Lu et al., 2022, arXiv:2211.01095). |
dpm2s | DPM-Solver++(2S) second-order singlestep variant (same paper). |
Fixed Pipeline
- Models: Stable Diffusion v1.5 and SDXL (frozen weights).
- Prompt set: shared evaluation prompts across all baselines.
- NFE budget: 20 denoiser calls per sample.
Evaluation
Evaluation runs text-to-image sampling on the model variants above. Metrics reported:
- CLIP score (cosine similarity between generated image and text prompt; higher is better).
- FID computed against a reference image set (lower is better).
Task scoring uses per-variant FID (lower is better). The method should improve image quality across variants without changing prompts, model weights, allowed function-evaluation budget, or metric computation.
Code
1@register_solver("ddim_cfg++")2class BaseDDIMCFGpp(StableDiffusion):3# TODO: Implement your improved sampling method here.4#5# You should implement an improved sampling algorithm that achieves better6# image quality (FID) with a fixed budget of NFE=50 steps.7#8# Key methods you need to implement:9# - __init__: Initialize the solver10# - sample: Main sampling function with your update rule11#12# Available helper methods from parent class:13# - self.get_text_embed(null_prompt, prompt): Get text embeddings14# - self.initialize_latent(): Initialize latent variable zT15# - self.predict_noise(zt, t, uc, c): Predict noise at timestep t
1@register_solver("ddim_cfg++")2class BaseDDIMCFGpp(StableDiffusion):3# TODO: Implement your improved sampling method here.4#5# You should implement an improved sampling algorithm that achieves better6# image quality (FID) with a fixed budget of NFE=50 steps.7#8# Key methods you need to implement:9# - __init__: Initialize the solver10# - sample: Main sampling function with your update rule11#12# Available helper methods from parent class:13# - self.get_text_embed(null_prompt, prompt): Get text embeddings14# - self.initialize_latent(): Initialize latent variable zT15# - self.predict_noise(zt, t, uc, c): Predict noise at timestep t
Method Summary
DPM++3M-SDE with cosine eta anneal
DPM-Solver++(3M) SDE on Karras sigmas, but eta cosine-anneals from 1.5 down to 0.5 across the 20 steps to balance early diversity and late detail.