Fused Causal Attention Kernel
Studies how fused self-attention kernels improve throughput and latency while preserving numerical agreement.
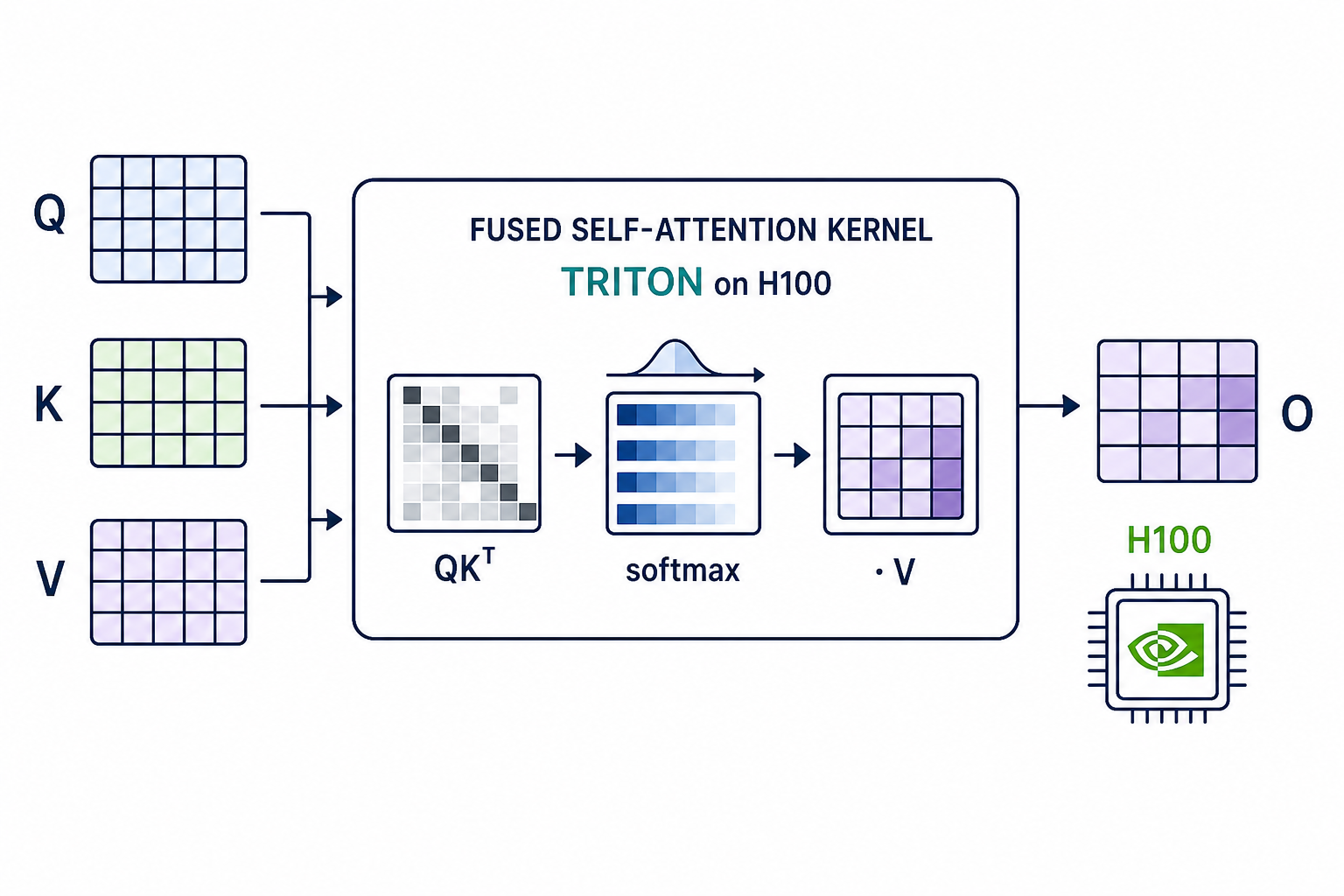
Description
Fused Attention Kernel Design for H100 GPUs
Research Question
Design an efficient fused self-attention forward pass kernel using OpenAI Triton that maximizes throughput (TFLOPs/s) on H100 GPUs while maintaining numerical correctness.
Background
Self-attention is the computational bottleneck of Transformer models. The standard implementation materializes the full N x N attention score matrix, requiring O(N^2) memory and O(N^2 d) FLOPs. FlashAttention (Dao et al., NeurIPS 2022; arXiv:2205.14135) introduced a tiled, IO-aware algorithm using online softmax that avoids materializing the full matrix, reducing HBM accesses from O(Nd + N^2) to O(N^2 d^2 / M) where M is SRAM size.
Subsequent versions improved throughput through better parallelism and hardware-specific optimizations:
- FlashAttention-2 (Dao, 2023; arXiv:2307.08691): reduced non-matmul FLOPs, parallelized over sequence length, better warp-level work partitioning.
- FlashAttention-3 (Shah et al., NeurIPS 2024; arXiv:2407.08608): exploits H100 Hopper features — warp specialization (producer/consumer warps overlapping TMA loads with GMMA compute), GEMM-softmax interleaving, and FP8 support. The paper reports ~740 TFLOPs/s on H100 in FP16 (~75% utilization).
Task
Modify the custom_attention_forward function and the associated Triton
kernel _custom_attn_fwd to implement an efficient fused attention
forward pass. You may:
- Redesign the tiling strategy (block sizes, tile shapes)
- Optimize the online softmax computation (e.g., use exp2 instead of exp, delay rescaling)
- Improve memory access patterns (coalescing, prefetching)
- Split the causal/non-causal iteration into separate passes to avoid per-block masking overhead
- Use Triton autotuning (
@triton.autotune) to search configurations - Define multiple helper kernels if needed
Interface
def custom_attention_forward(q, k, v, causal=True, sm_scale=None):
"""
Args:
q, k, v: (batch, nheads, seqlen, headdim), contiguous, FP16
causal: if True, apply causal mask (key_pos <= query_pos)
sm_scale: softmax scale factor (default: 1/sqrt(headdim))
Returns:
output: (batch, nheads, seqlen, headdim), same dtype as input
"""Correctness constraint: max absolute difference from reference (PyTorch
SDPA) must be < 1e-2.
Evaluation
Benchmarked on multiple causal configurations aligned with the FA3 paper (total tokens = 16384):
| Config | Batch | SeqLen | Heads | HeadDim |
|---|---|---|---|---|
hdim64_seq4k | 4 | 4096 | 32 | 64 |
hdim128_seq8k | 2 | 8192 | 16 | 128 |
hdim256_seq16k | 1 | 16384 | 8 | 256 |
All configurations use FP16, causal masking, on H100 80GB SXM5.
Metrics (per configuration):
tflops: achieved TFLOPs/s (higher is better) — primary metriclatency_ms: kernel latency in milliseconds (lower is better)correct: binary (1 ifmax_diff < 1e-2, else 0) — hard constraint
FLOP formula (FA2/FA3 convention):
4 * batch * seqlen^2 * nheads * headdim / 2 (causal).
Hints
- The default template provides a basic flash attention kernel. Key
optimization opportunities:
- Two-pass causal: split the K/V loop into non-causal blocks (no mask check) and causal boundary blocks, reducing branch overhead
- Block size tuning: different
(BLOCK_M, BLOCK_N)for different headdims — larger blocks amortize loop overhead but increase register pressure - Triton autotuning: use
@triton.autotunewithconfigs=[...]to search block sizes at compile time - Reduced rescaling: in the online softmax, the rescaling
acc *= alphacan be deferred or batched to reduce non-matmul operations - Memory coalescing: ensure K/V loads are coalesced along the headdim dimension
- The Triton tutorial fused attention demonstrates the two-pass approach
- FA3 achieves its speedup through Hopper-specific CUDA features (warp specialization, TMA, GMMA) that are not directly accessible from Triton — closing the gap requires algorithmic cleverness in the Triton DSL
- Available imports:
torch,triton,triton.language as tl,math,torch.nn.functional as F
Code
1"""Fused Attention Kernel Benchmark — H100 GPU.23Benchmark harness for evaluating custom Triton attention kernels.4Aligned with Flash Attention 3 (Shah et al., NeurIPS 2024) benchmarks.5FLOP formula (FA2/FA3): 4 * batch * seqlen^2 * nheads * headdim (halved for causal).6Total tokens fixed at 16384 (batch = 16384 / seqlen).7"""89import argparse10import math11import os12import time1314import torch15import torch.nn.functional as F
Method Summary
Two-pass Causal + Wide Autotune Sweep
Flash-v3-style two-pass causal kernel with fused log2(e)*scale into Q and an enlarged 19-config autotune sweep across (BLOCK_M, BLOCK_N, num_stages, num_warps).
1. wrapper: , then launch autotuned _custom_attn_fwd2. kernel: each (m_block, head) program loads Q tile once3. pass 1 — non-causal blocks (no mask, no boundary check):for in :; online-softmax in ; acc += PV4. pass 2 — causal-boundary blocks:for in :← ; same online-softmax update5. acc /= l_i; store OAutotune key = (seqlen, BLOCK_DMODEL, IS_CAUSAL); sweeps BLOCK_M ∈ {16, 32, 64, 128, 256}, BLOCK_N ∈ {32, 64, 128}, num_stages ∈ {2..4}, num_warps ∈ {4, 8}